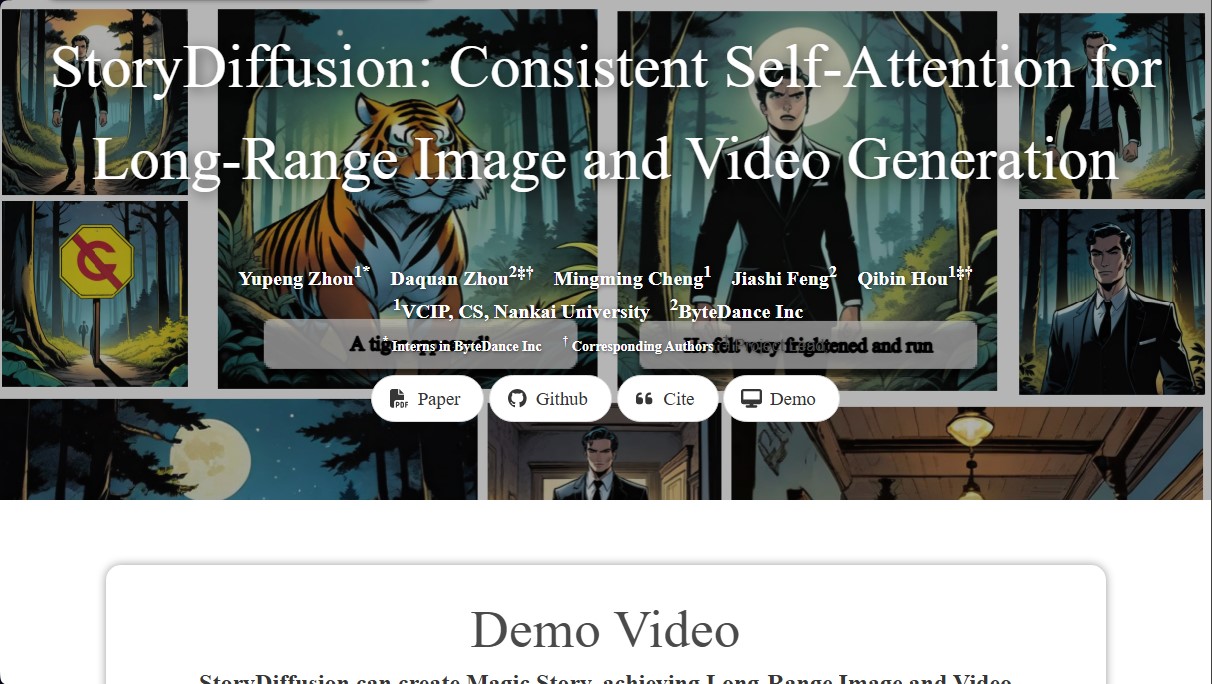
StoryDiffusion
Share
StoryDiffusion
Generate comics and long-form videos with consistent characters. Maintain visual consistency across multiple subjects in narrative sequences created from text.
General Information about StoryDiffusion
StoryDiffusion is an artificial intelligence solution specializing in the generation of images and long-form videos with a strict focus on narrative consistency. Its primary function is to allow users to create visual sequences, such as comics or audiovisual pieces, where characters and environments maintain a consistent appearance despite changes in framing or action. This tool solves the technical issue of inconsistency found in traditional diffusion models, facilitating the efficient creation of complex visual stories from a computer.
The operation of StoryDiffusion is based on an innovative architecture that introduces Consistent Self-Attention. This mechanism allows the AI model to process a batch of images simultaneously, establishing links between them so that elements such as clothing, facial features, and artistic style remain stable. The system breaks down a narrative text into multiple prompts and generates them in a coordinated fashion, ensuring the subject is perfectly recognizable in every panel or frame of the sequence.
Among its most notable functional capabilities are:
- Comic and graphic novel generation: Enables the creation of complete stories in various artistic styles while maintaining a cohesive aesthetic throughout the entire work.
- Multi-character consistency: Advanced capability to manage and differentiate the identities of multiple characters simultaneously within the same series of images.
- Cartoon-style character creation: Optimized for generating cartoon protagonists with persistent traits and appealing designs.
- Video generation via Motion Predictor: Uses a motion predictor in semantic space to create fluid transitions between images, resulting in stable and realistic long-form videos.
For video production, StoryDiffusion employs the Semantic Motion Predictor, a module that estimates motion conditions between two provided images. By encoding information in a semantic space rather than being limited solely to latent space, the tool achieves superior precision in predicting high-motion transitions. This allows a sequence of static images to be transformed into high-quality video clips where the subject does not deform or change identity during the animation—a fundamental requirement for visual storytelling.
This technology is applied in a zero-shot manner over pre-trained text-to-image diffusion models, meaning it enhances the capabilities of existing models without the need for additional training processes. It is a consistent visual content generation tool designed for creators looking to automate the production of graphic narratives or animations with a professional and consistent technical finish.
Features and Use Cases of StoryDiffusion
How StoryDiffusion Works
Frequently Asked Questions about StoryDiffusion
What is StoryDiffusion and what does it do?
It is a system designed to create long-form comics and videos while maintaining complete visual consistency across characters and backgrounds.
How does StoryDiffusion maintain character consistency?
It uses a "Consistent Self-Attention" mechanism that links batch-generated images, ensuring that clothing and style remain uniform.
Can I create comics with multiple characters at the same time?
Yes, the tool allows you to generate and maintain the identity of multiple characters simultaneously across an entire image sequence.
What is the role of the motion predictor in StoryDiffusion?
This module predicts transitions between images to turn static sequences into smooth videos with natural, consistent motion.
Can I generate cartoon-style characters?
Yes, the platform can create impressive cartoon characters while keeping their appearance consistent across various scenes and contexts.
Can I use my own photos as a starting point in StoryDiffusion?
Absolutely. You can upload your own images for the system to use as a reference when generating video transitions.
Does this tool require special training for existing models?
No, it works directly with existing text-to-image diffusion models, enhancing consistency without the need for additional training.
What sets StoryDiffusion apart from other video generators?
Its main advantage is the ability to generate long-form content with much higher stability, thanks to its semantic motion predictor.
StoryDiffusion Pricing
Clear information regarding pricing plans or subscription fees is not available in the provided details. We recommend visiting the official website for the most up-to-date information on access and potential costs for the tool.
StoryDiffusion Screenshots