Google acaba de confirmar oficialmente Gemini 3.1 Flash-Lite, y la jugada es clarísima: más velocidad, menos latencia y un precio reducido a la mitad para quienes viven de llamar a modelos mediante API.
Si estás construyendo un producto con IA, el problema no suele ser únicamente “la inteligencia” del modelo, sino el coste por token y el tiempo que el usuario pasa esperando mientras algo carga. En ese contexto, cada milisegundo cuenta y cada llamada a la API también.
En concreto, Google lo presenta como el modelo más rápido y barato de la familia Gemini, y además es el que se utiliza mayoritariamente como base dentro de la propia app de Gemini, aunque en una variante optimizada. Sin embargo, lo realmente interesante no es el marketing, sino responder a la pregunta clave: si reducir la latencia implica sacrificar calidad.
El mensaje entre líneas es bastante claro: Gemini 3.1 Flash-Lite está diseñado para mover grandes volúmenes de datos sin que el desarrollador tenga que recalcular constantemente cuánto cuesta el sistema.
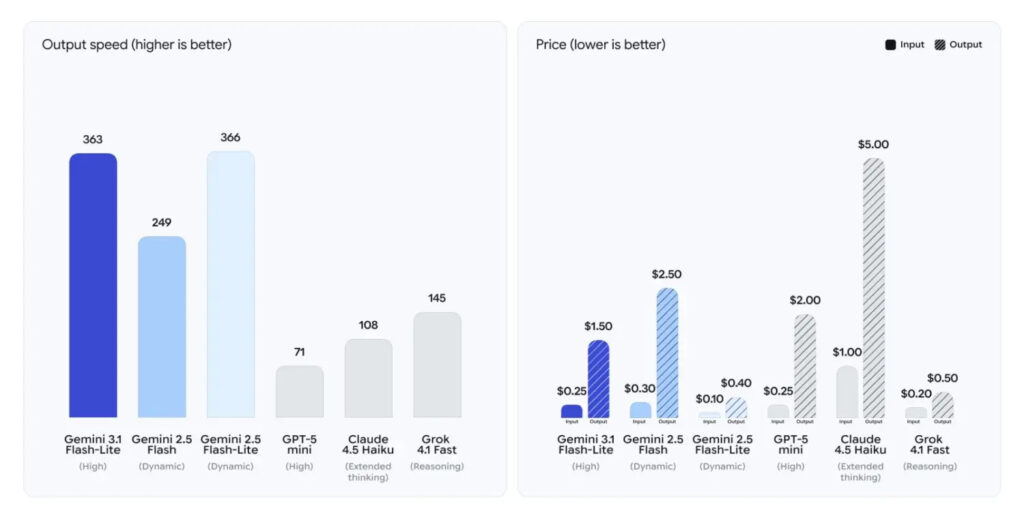
En términos de rendimiento, Google afirma que el modelo responde hasta 2,5 veces más rápido que Gemini 2.5 Flash. Esto no es una mejora teórica que solo se aprecia en benchmarks; es el tipo de diferencia que realmente se nota en productos reales: chats en vivo, agentes que ejecutan pasos encadenados, clasificación automática de tickets, resúmenes instantáneos o pipelines donde cada segundo extra se multiplica por miles de llamadas.
A este dato se suma un indicador externo interesante. Según benchmarks de Artificial Analysis, Flash-Lite sería aproximadamente un 45% más rápido generando respuestas que Gemini 2.5 Flash.
Ahora bien, la velocidad por sí sola no sirve de mucho si el modelo empieza a inventarse información o pierde precisión en tareas que requieren razonamiento. Por eso, además de hablar de rapidez, Google intenta respaldar el rendimiento con métricas de calidad.
Uno de los datos más llamativos aparece en Arena.ai, donde el modelo figura con una puntuación Elo de 1432. Esta cifra no es simplemente decorativa para una diapositiva de marketing: ese rango suele indicar que el modelo compite con bastante dignidad en comparativas ciegas de calidad percibida.
Pero donde Google realmente intenta demostrar músculo es en pruebas que se parecen más a usos reales. Por ejemplo, alcanza un 86,9% en GPQA Diamond, un benchmark que mide razonamiento profundo con preguntas de nivel experto. Este tipo de evaluación suele revelar si el modelo comprende realmente el problema o si simplemente se limita a “autocompletar con estilo”.
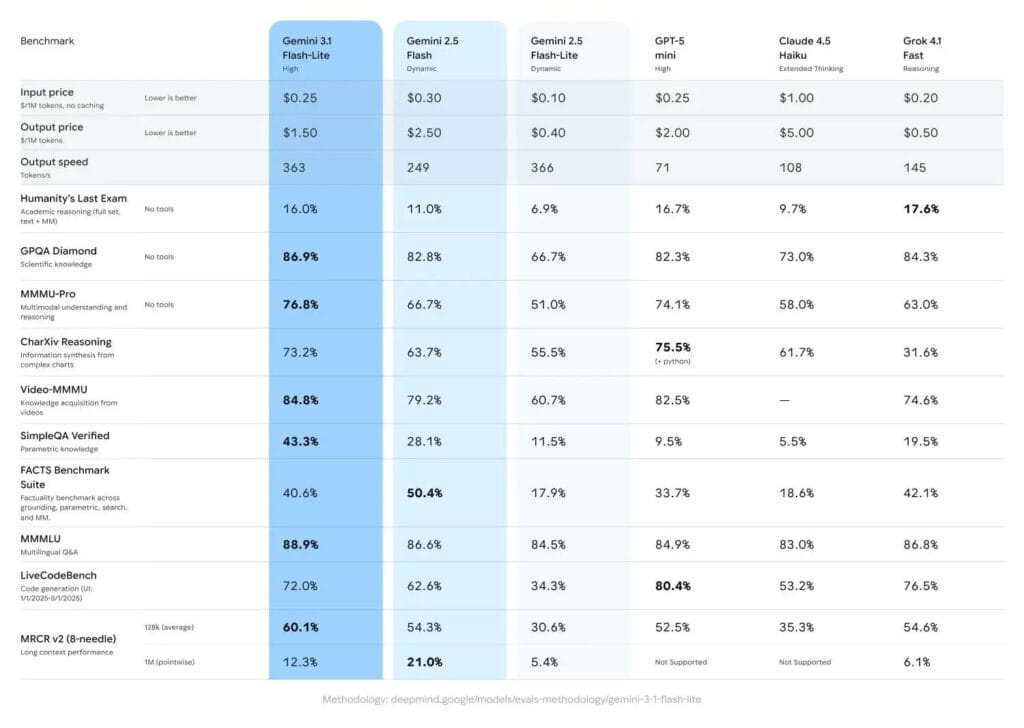
A ello se suma otro indicador relevante: un 76,8% en MMMU Pro, una prueba centrada en multimodalidad. En este caso, no se trata del típico ejemplo de demo donde el modelo describe una imagen, sino de problemas que combinan texto e imagen en distintas disciplinas, lo que exige una comprensión más amplia.
Además, Google lo compara —al menos en su narrativa de benchmarks— con rivales directos dentro del segmento de modelos rápidos: GPT-5 mini, Claude 4.5 Haiku y Grok 4.1 Flash. La idea que intenta transmitir es bastante evidente: “soy pequeño, pero puedo razonar como uno grande”, destacando especialmente en conocimiento científico, comprensión de vídeo y razonamiento en distintos idiomas.
Aun así, con los benchmarks siempre conviene mantener cierta cautela. El dataset utilizado, el tipo de prompt, la temperatura del modelo e incluso la versión evaluada pueden influir mucho en los resultados, por lo que estas comparativas suelen ser más una referencia inicial que una conclusión definitiva.
Uno de los aspectos más interesantes para quienes desarrollan productos es que el modelo hereda el control de niveles de pensamiento.
En la práctica, esto permite ajustar cuánta “gasolina computacional” utiliza el modelo según la tarea. De esta manera, puedes pedirle más esfuerzo cuando el problema lo requiere —por ejemplo, al generar una interfaz de usuario o planificar un flujo complejo— y reducir ese nivel cuando la tarea es sencilla, como una traducción o una clasificación básica.
El beneficio es inmediato: menos gasto operativo y menos latencia cuando no necesitas el modo de razonamiento máximo. En entornos donde se realizan miles o millones de llamadas al modelo, este tipo de control puede marcar una diferencia enorme en el coste total del sistema.
Cuando se lanzó Gemini 3 Flash, el precio era de 0,50 dólares por millón de tokens de entrada y 3 dólares por millón de tokens de salida. Para muchas start-ups, esa cifra es precisamente el punto donde comienzan los cálculos incómodos y las decisiones de producto que obligan a recortar funcionalidades.
Con Gemini 3.1 Flash-Lite, la cifra cambia de forma directa: 0,25 dólares por millón de tokens de entrada y 1,50 dólares por millón de tokens de salida. En otras palabras, un 50% menos en ambos lados, lo que simplifica enormemente las cuentas para cualquier equipo que esté construyendo sobre esta infraestructura.
Este recorte revela también el objetivo estratégico: convertirse en el modelo por defecto cuando necesitas respuestas instantáneas y llamadas masivas, especialmente en productos donde la IA está siempre activa.
No todo es perfecto. En tareas de programación, Flash-Lite queda por detrás en benchmarks como LiveCodeBench, y no logra superar a modelos como GPT-5 mini o Grok 4.1 Fast. Esto significa que, si lo que buscas es un copiloto de código capaz de escribir soluciones complejas o muy optimizadas, probablemente existan alternativas más adecuadas.

De hecho, la propia posición de Google parece bastante clara. Flash-Lite se presenta más como un motor eficiente para seguir instrucciones complejas dentro de procesos repetitivos, en lugar de un “ingeniero senior sintético” especializado en programación.
En cuanto a disponibilidad, Gemini 3.1 Flash-Lite ya está accesible en vista previa, y se espera que pronto se libere oficialmente para desarrolladores.
Como suele ocurrir con los productos de Google, el acceso sigue dos caminos principales. Por un lado, la versión preliminar vía API en Google AI Studio; por otro, la integración empresarial a través de Vertex AI, donde las compañías pueden desplegar el modelo dentro de sus propios sistemas.
El encaje de producto parece bastante definido. Flash-Lite apunta directamente a desarrolladores que priorizan coste y latencia, mientras que Gemini 3.1 Flash queda como una opción más equilibrada para experiencias de usuario final.
Si el rendimiento cumple lo que promete, la consecuencia es bastante clara: veremos cada vez más aplicaciones con IA “siempre encendida” y menos excusas relacionadas con el coste de operación. En ese escenario, la presión recae ahora sobre el resto del mercado, que tendrá que responder con mejores precios, mayor eficiencia… o modelos que, además de rápidos, también destaquen escribiendo código sin despeinarse.
Me dedico al SEO y la monetización con proyectos propios desde 2019. Un friki de las nuevas tecnologías desde que tengo uso de razón.
Estoy loco por la Inteligencia Artificial y la automatización.

La Newsletter Diaria Sobre Inteligencia Artificial. Además: Portal de Noticias, Tutoriales, Tips y Trucos de ChatGpt, Openai e Inteligencia Artificial.
Nuestra web está alojada en:


