Alibaba ha presentado Qwen-3-Max, un modelo de lenguaje con un billón de parámetros que busca marcar un antes y un después. La cifra impresiona y coloca a China en primer plano, pero falta un detalle clave para entender si esto cambia el juego.
El anuncio llega pocos meses después del estreno de la serie Qwen3, lanzada en mayo de este año. Qwen-3-Max es el más grande de la familia y sube el listón desde los 235.000 millones de parámetros en los modelos anteriores hasta un billón de parámetros.
Según el South China Morning Post, el nuevo Qwen-3-Max destaca en comprensión, razonamiento y generación de texto.

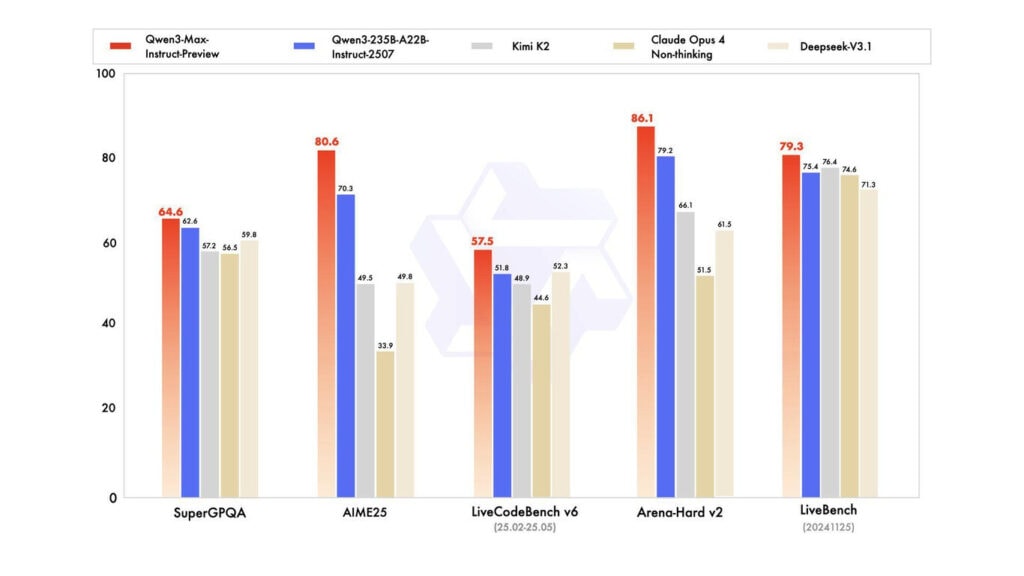
En pruebas de benchmarking, Qwen-3-Max aparece por delante de Claude Opus 4, DeepSeek V3.1 y Kimi K2 cuando la tarea exige respuesta rápida. Falta matizar qué tipo de pruebas miramos. Modelos enfocados al razonamiento, como Gemini 2.5 Pro o GPT-5, no compiten en esa categoría y mantienen ventaja clara en matemáticas y código.
De hecho, en 2022 DeepMind mostró algo incómodo para la carrera por inflar cifras. Chinchilla, con 70.000 millones de parámetros y cuatro veces más datos que otros modelos, superó a Gopher, que tenía muchos más parámetros. Entonces, entrenar mejor gana a crecer por crecer, y eso sigue vigente hoy para Qwen-3-Max.
Hay otro ángulo que te conviene mirar: la arquitectura. Técnicas como Mixture of Experts dividen el modelo en expertos más pequeños y activan solo el que toca en cada consulta. Con esto, vas a poder reducir coste y tiempo de respuesta. Mistral lo usa para ejecutar solo una fracción de sus parámetros y así ser más rápido y barato.

Si Qwen-3-Max adopta o optimiza enfoques de este tipo, el billón de parámetros no tendría por qué disparar el coste de servir cada petición. La eficiencia depende de combinar varias cosas: datos limpios, arquitectura bien afinada y objetivos de uso claros. Si una pieza falla, el rendimiento real se resiente.
Sobre el terreno, Qwen-3-Max ya se puede tocar. Qwen-3-Max-preview ya se puede probar gratis, lo que ayuda a medir si encaja en tus flujos. Si comparas con Gemini 2.5 Pro o con GPT-5 en tareas de matemáticas o programación, verás que siguen ganando. Pero si priorizas respuesta rápida en lenguaje general, el nuevo modelo chino puede darte una ventaja tangible.
Próximos pasos que merece la pena vigilar: si Alibaba publica más detalles de datos de entrenamiento, sabrás mejor dónde brilla Qwen-3-Max. Si aparece una versión Mixture of Experts o una variante ligera, prepárate para bajadas de latencia y precio por consulta. Y si ves mejoras en matemáticas y código, podríamos asistir a un salto hacia el terreno de los modelos de razonamiento.
Hoy, la señal práctica es clara: Qwen-3-Max te ayudará en comprensión del lenguaje, razonamiento cotidiano y generación de texto con tiempos ágiles. La decisión no va solo de tamaño. Mira datos, arquitectura y uso real, porque ahí se decide la calidad. Y sí, el billón de parámetros impresiona, pero te conviene medirlo en resultados que te ahorren tiempo y coste.
Me dedico al SEO y la monetización con proyectos propios desde 2019. Un friki de las nuevas tecnologías desde que tengo uso de razón.
Estoy loco por la Inteligencia Artificial y la automatización.

La Newsletter Diaria Sobre Inteligencia Artificial. Además: Portal de Noticias, Tutoriales, Tips y Trucos de ChatGpt, Openai e Inteligencia Artificial.
Nuestra web está alojada en:


