Alibaba Cloud ha presentado esta semana Qwen3-Next, una familia de modelos de lenguaje que promete el mismo trabajo por una fracción del coste. La noticia importa porque choca con la lógica actual de la IA generativa: más grande suele significar más caro.
La compañía china describe Qwen3-Next como “el futuro de los LLMs eficientes”, y lo lanza desde su división de nube. ¿Qué hay detrás? Un conjunto de modelos muy afinados donde destaca Qwen3-Next-80B-A3B. Son hasta trece veces más pequeños que su modelo estrella de hace una semana, y esa reducción no llega sola. El tamaño no es lo más interesante.
El punto llamativo está en la velocidad y en la factura de cómputo. Qwen3-Next-80B-A3B es hasta diez veces más rápido que Qwen3-32B (abril), y reduce el coste de entrenamiento un 90 % frente a su predecesor directo. Vas a poder intuir hacia dónde va el sector con solo mirar las cifras de inversión.
Según el AI Index Report de Stanford (2024), entrenar GPT-4 costó 78 millones de dólares, y Gemini Ultra llegó a 191 millones. Qwen3-Next, en cambio, se estima en 500.000 dólares. El contraste es enorme, pero la pregunta real es cómo se logra esa diferencia sin destrozar el rendimiento.
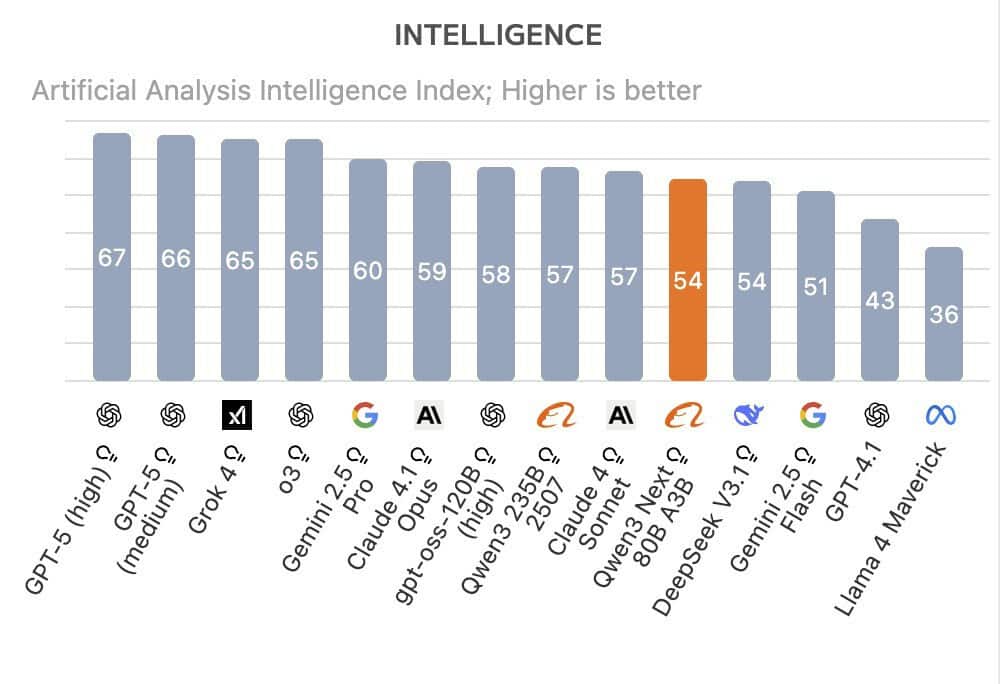
En pruebas de Artificial Analysis, Qwen3-Next-80B-A3B supera a DeepSeek R1 y a Kimi-K2 en razonamiento. Si lo comparas con gigantes como GPT-5, Grok 4, Gemini 2.5 Pro o Claude 4.1 Opus, todavía están por delante en evaluación global. Con todo, el resultado por euro gastado es difícil de ignorar.
La base técnica es Mixture of Experts (MoE), un enfoque que divide el modelo en “expertos” especializados. Qwen3-Next-80B-A3B integra 512 expertos, pero solo activa 10 a la vez, así se concentra la potencia donde hace falta y se ahorra cómputo cuando no. DeepSeek-V3 usa 256, Kimi-K2 llega a 384; aquí, más expertos y menos activación simultánea.
Con Gated DeltaNet, Qwen3-Next-80B-A3B se acerca al rendimiento del enorme Qwen3-235B-A22B-Thinking-2507, pero con mucha menos carga de cómputo. Para tareas reales, eso significa respuestas rápidas, menos latencia y facturas previsibles. Falta ver cómo escala fuera del laboratorio, y ese examen llega pronto.
La clave es una combinación de diseño y foco. MoE apaga la mayoría de expertos en cada paso, la atención híbrida recorta lo irrelevante y el tamaño total baja sin perder músculo útil. En números: trece veces más pequeño que el modelo grande de la semana anterior y diez veces más veloz que Qwen3-32B. Esa mezcla explica la caída del 90 % en costes frente a su predecesor.
Este movimiento llega en un contexto de costes al alza. Tencent presentó el mes pasado modelos con menos de 7.000 millones de parámetros, y la startup Z.ai lanzó GLM-4.5 Air con 12.000 millones activos. La idea es clara: modelos más pequeños, más baratos de entrenar y mejor ajustados a tareas concretas. Qwen3-Next se alinea con esa corriente y la lleva un paso más lejos en eficiencia.

Qwen3-Next plantea un mensaje directo: no necesitas gastar 78 millones si puedes llegar muy cerca por 500.000. La familia Qwen3-Next no bate a todos en todo, pero cambia el cálculo coste/rendimiento con MoE, atención híbrida y Gated DeltaNet. El verdadero examen será fuera del paper y del benchmark, en producción diaria y con usuarios reales.
Me dedico al SEO y la monetización con proyectos propios desde 2019. Un friki de las nuevas tecnologías desde que tengo uso de razón.
Estoy loco por la Inteligencia Artificial y la automatización.

La Newsletter Diaria Sobre Inteligencia Artificial. Además: Portal de Noticias, Tutoriales, Tips y Trucos de ChatGpt, Openai e Inteligencia Artificial.
Nuestra web está alojada en:


