¿Buscas bajar el precio de tus llamadas a la API cuando cargas documentos largos? DeepSeek acaba de presentar un modelo que quiere cambiar ese cálculo. Te contamos qué hay detrás de su propuesta, cómo funciona la nueva atención dispersa y por qué podrías recortar costes de inferencia sin tocar la calidad del resultado.
La idea suena clara: procesar más contexto con menos carga de servidor y, por tanto, pagar menos. Lo interesante no es solo la promesa, sino el mecanismo técnico que la hace plausible y la disponibilidad de pesos abiertos para que tú mismo lo pruebes, lo midas y lo adaptes a tu flujo de trabajo.
DeepSeek V3.2-exp es un modelo experimental pensado para operaciones de contexto prolongado donde normalmente se disparan los costes de inferencia. La propuesta se centra en una arquitectura de sparse attention que intenta leer lo importante y saltarse lo irrelevante, manteniendo una ventana de atención limitada pero eficaz.

Con esta estrategia puedes trabajar con fragmentos extensos sin saturar la memoria del servidor. Con todo, el valor diferencial está en cómo decide qué partes del contexto merecen entrar en la ventana de atención y en qué orden, porque ahí es donde se gana o se pierde precio por consulta.
El núcleo del sistema es DeepSeek Sparse Attention, una atención “parca” que elige focos de información en vez de barrerlo todo. Para lograrlo, integra un módulo llamado “lightning indexer” que prioriza fragmentos clave de la ventana de contexto en función de su relevancia para la tarea actual.
Gracias a esa priorización inicial, el modelo evita cargar bloques enormes en la atención completa, lo que reduce de forma directa los costes de inferencia. La selección fina de tokens es la pieza que termina de ajustar el consumo real por petición.
También te puede interesar:Tras Desaparecer por Meses, Investigador Jefe de Deepseek alerta de Algo que Afectará al TrabajoTras ordenar los fragmentos, entra en juego el “fine-grained token selection system”. Este sistema elige tokens concretos dentro de cada bloque prioritario para meterlos en la ventana de atención limitada, una especie de filtro quirúrgico que afina el contenido útil.
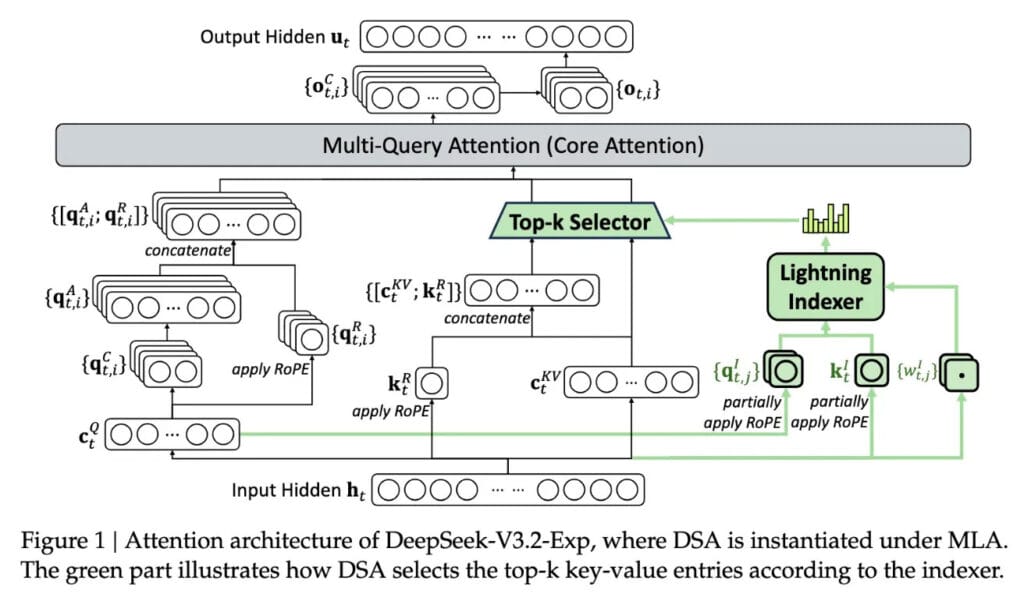
Esa combinación de indexado rápido y selección detallada permite procesar porciones largas manteniendo cargas modestas. El resultado práctico es claro: menos tokens activos en atención total y, por tanto, menores costes de inferencia en escenarios de contexto largo.
Las pruebas internas de la compañía apuntan a que el coste de una simple llamada a la API podría caer hasta la mitad cuando trabajas con contextos extensos. No hablamos de microahorros, sino de un recorte significativo que puedes notar en pocas horas de uso intensivo.
Son resultados preliminares y faltan réplicas externas. En cualquier caso, si sueles procesar contratos, chats históricos o logs largos, notarás una baja directa en costes de inferencia por sesión y por usuario.
Para despejar dudas, el modelo se publica con pesos abiertos y está disponible en Hugging Face. Eso permite que terceros lo sometan a bancos de pruebas realistas, comparen métricas, midan latencias y verifiquen la prometida reducción de costes de inferencia con datos independientes.
Recuerda ajustar tu pipeline: distribuye el contexto en fragmentos, define criterios de relevancia y registra el coste por token. Solo así podrás reproducir, con sentido, lo que el paper describe a alto nivel.
También te puede interesar:DeepSeek Impulsa un Cambio Silencioso en la Industria China y Deja un Interrogante Sobre su HonestidadCuando hablamos de IA en producción, el gasto que duele cada día son los costes de inferencia, es decir, lo que pagas para servir peticiones en tiempo real. Ese coste no es el mismo que el del entrenamiento, que se paga una vez y se amortiza con el uso.
DeepSeek se ha centrado justo en ese punto: bajar el precio por consulta sin rehacer todo el proceso de entrenamiento. Con todo, su enfoque encaja con una tendencia del sector que busca eficiencia operativa antes que modelos cada vez más grandes sin límite práctico.
El equipo exploró formas de hacer más eficiente la arquitectura transformadora básica y concluyó que hay margen significativo de mejora. La atención dispersa no es magia, pero sí una vía concreta para recortar costes de inferencia cuando el contexto crece más rápido que el presupuesto.
Si lo comparamos con la app móvil de un servicio web, aquí la optimización no es el frontend, sino el modo en que el modelo decide a qué prestar atención. Esa decisión impacta en memoria, latencia y precio por llamada, y ahí es donde V3.2-exp intenta marcar la diferencia.
DeepSeek, con sede en China, se ha convertido en un actor visible en un panorama que muchos ven como una competición continua entre EE. UU. y China. Su propuesta pone el foco en la economía del despliegue, no solo en el rendimiento bruto.
Lo relevante no es la bandera, sino si tú bajarás tus costes de inferencia sin sacrificar calidad. En la práctica, esta clase de mejoras técnicas suele acabar integrada en librerías, SDK y frameworks que usamos a diario.
A inicios de año DeepSeek sorprendió con R1, entrenado en gran parte con reforzamiento y a un precio menor que sus rivales estadounidenses. Aquello levantó expectativas enormes en torno al entrenamiento barato y rápido.
La realidad fue distinta: R1 no provocó una revolución generalizada y la empresa perdió parte de su foco público en los meses siguientes. V3.2-exp adopta un rumbo más pragmático, con sparse attention que puede dar a proveedores estadounidenses y a cualquiera estrategias concretas para mantener bajos los costes de inferencia.
¿Quieres validar la promesa en tu caso real? Prepara un entorno de pruebas con tus documentos típicos y marca métricas claras de precio y latencia. Recuerda que cada stack es un mundo. Ajusta lotes, usa caché cuando convenga y captura los tokens facturados por petición. Con todo, verás si la atención dispersa te compensa en tu flujo.
V3.2-exp pone sobre la mesa una forma tangible de recortar costes de inferencia en contexto largo gracias a DeepSeek Sparse Attention, al “lightning indexer” y a la selección fina de tokens. Las pruebas internas hablan de una reducción del 50 %, y con pesos abiertos en Hugging Face, puedes comprobarlo en tu caso. Si tu prioridad es bajar el coste por llamada manteniendo calidad, este enfoque merece una prueba seria.
Me dedico al SEO y la monetización con proyectos propios desde 2019. Un friki de las nuevas tecnologías desde que tengo uso de razón.
Estoy loco por la Inteligencia Artificial y la automatización.

La Newsletter Diaria Sobre Inteligencia Artificial. Además: Portal de Noticias, Tutoriales, Tips y Trucos de ChatGpt, Openai e Inteligencia Artificial.
Nuestra web está alojada en:


