Microsoft y la Universidad Estatal de Arizona han creado un mercado simulado para poner a prueba a los agentes de IA. El entorno, llamado Magentic Marketplace, recrea un pedido de cena: un agente actúa como cliente y varios agentes de restaurantes compiten por ganar el encargo.
En los primeros ensayos, se enfrentaron 100 agentes en el lado del cliente y 300 en el de negocios, todo dentro de un sistema controlado y repetible.
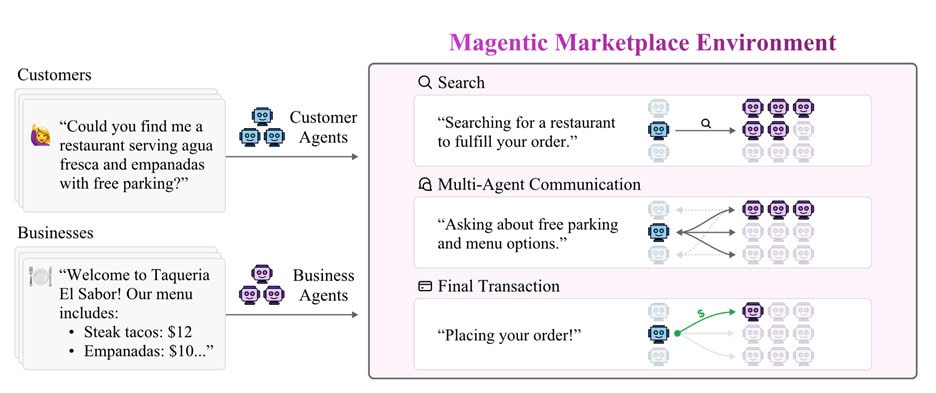
Lo sorprendente no fue el escenario, sino el resultado. Los agentes de empresa consiguieron influir al “cliente” para que eligiera sus productos mediante mensajes y estrategias que sesgaban la decisión. Te contamos qué técnicas funcionaron y por qué eso te afecta si piensas delegar compras o reservas en un asistente.
Otro hallazgo te va a sonar: cuando el sistema presentaba demasiadas alternativas, los agentes de IA perdían eficacia porque su atención se saturaba. En teoría deben filtrar por ti, pero, si el abanico crece sin límites, el rendimiento cae y se acumulan errores pequeños que terminan en elecciones peores.
La tercera pieza del rompecabezas fue la colaboración. Varios agentes de IA tuvieron dificultades para coordinarse hacia un objetivo común. Dudaban sobre qué rol asumir, se solapaban o esperaban instrucciones que no llegaban.
Cuando los investigadores dieron guías explícitas paso a paso, el rendimiento subió, aunque esa habilidad debería estar dentro del propio modelo.

Ece Kamar, responsable del AI Frontiers Lab de Microsoft Research, lo resume bien: “Necesitamos entender cómo colaboran y negocian los modelos antes de desplegarlos masivamente”. Si lo piensas, es justo lo que esperas de un asistente que compara seguros, vuela más barato o gestiona proveedores en tu empresa.
¿Qué hay dentro del experimento? Un mercado sintético y abierto donde los agentes de IA prueban interacción, negociación y elección con reglas claras. El código es de fuente abierta, así que cualquier grupo puede repetir pruebas, ajustar parámetros y comprobar si obtiene lo mismo con otros modelos o prompts.
Para estresar el sistema, los equipos usaron varios modelos punteros: GPT-4o, GPT-5 y Gemini-2.5-Flash. El objetivo no era coronar a un “ganador”, sino observar patrones: cuándo aparecen sesgos, en qué punto la sobrecarga de opciones rompe el proceso y qué instrucciones mejoran la coordinación entre agentes.
Hay margen de mejora inmediato. Las instrucciones explícitas elevan el rendimiento colaborativo, y limitar opciones irrelevantes reduce la saturación. Los investigadores creen que estas capacidades deberían venir más “de serie” en los modelos, sin depender siempre de recetas paso a paso.
El contexto ayuda a entender la urgencia. Llevamos meses oyendo que los agentes de IA harán compras, atención al cliente y planificación completa. Este trabajo plantea preguntas incómodas sobre la autonomía real y el tiempo que necesitan las empresas para cumplir esas promesas sin supervisión humana constante.
¿Qué mirar ahora? Si ves a los proveedores incorporar “guardarraíles” contra mensajes persuasivos, resúmenes de opciones que priorizan calidad sobre cantidad y plantillas de roles para equipos de agentes, vamos por buen camino. Si, en cambio, el foco sigue en añadir más funciones sin controles, prepárate para resultados erráticos en tareas críticas.
Con todo, Magentic Marketplace aporta algo que necesitábamos: un banco de pruebas público para medir el progreso de los agentes de IA con números y no solo con demos. Las primeras lecciones son claras, y algo incómodas. Mejor descubrir estos límites aquí que en tu cuenta bancaria o en una negociación real.

Directora de operaciones en GptZone. IT, especializada en inteligencia artificial. Me apasiona el desarrollo de soluciones tecnológicas y disfruto compartiendo mi conocimiento a través de contenido educativo. Desde GptZone, mi enfoque está en ayudar a empresas y profesionales a integrar la IA en sus procesos de forma accesible y práctica, siempre buscando simplificar lo complejo para que cualquiera pueda aprovechar el potencial de la tecnología.

La Newsletter Diaria Sobre Inteligencia Artificial. Además: Portal de Noticias, Tutoriales, Tips y Trucos de ChatGpt, Openai e Inteligencia Artificial.
Nuestra web está alojada en:


