Con Mistral Large 3 y la familia Mistral 3 pasa una cosa curiosa: los números técnicos acompañan bastante bien al titular, pero lo interesante para ti no son solo los parámetros, sino qué vas a poder hacer con ellos en tus proyectos reales.
Si trabajas con IA generativa, ya sea desde una empresa, como desarrollador independiente o dentro de una comunidad de código abierto, esta nueva familia mezcla tres cosas que suelen ser difíciles de ver juntas: pesos abiertos, buen rendimiento y un enfoque claro en despliegues multilingües y multimodales.
Para entender por qué Mistral Large 3 está llamando tanta atención, conviene empezar por su estructura. Este modelo insignia se apoya en una arquitectura de mixture of experts dispersa, conocida como sparse MoE. En esta configuración no se activan todos los parámetros a la vez, sino que se seleccionan expertos específicos para cada tramo de texto, lo que te permite combinar mucha capacidad con un consumo razonable de recursos.
En números, Mistral Large 3 maneja unos 41.000 millones de parámetros activos en cada inferencia, pero cuenta con un total de 675.000 millones de parámetros repartidos entre esos expertos. Esa diferencia entre parámetros activos y totales es lo que marca la gracia del enfoque MoE: tienes una red enorme, pero solo “despiertas” lo necesario en cada consulta, algo clave si vas a servir tráfico desde GPU compartidas o servicios en la nube.
Si te preguntas dónde encaja Mistral Large 3 dentro de la familia, la respuesta es que la serie Mistral 3 no se limita al modelo grande. Incluye también tres modelos compactos y densos con 3.000, 8.000 y 14.000 millones de parámetros, pensados para casos en los que no necesitas tanta potencia o no puedes permitirte una GPU de gama alta.

Gracias a esta variedad, vas a poder elegir el tamaño de modelo que mejor se adapte a tu caso: quizá quieras el de 3B para ejecutar en un dispositivo cercano al edge, el de 8B para una API interna de la empresa, y el de 14B para tareas de análisis más pesadas. La idea es que la familia Mistral 3 se adapte tanto a un prototipo ligero como a un servicio de producción estable.
Una de las preguntas habituales cuando miras modelos avanzados es qué puedes hacer legalmente con ellos. En el caso de Mistral 3, todos los modelos son de código abierto y se publican bajo licencia Apache 2.0. Esto significa que vas a poder usarlos en proyectos comerciales, modificarlos, integrarlos en tus productos y redistribuirlos, siempre respetando las condiciones de esa licencia permisiva.
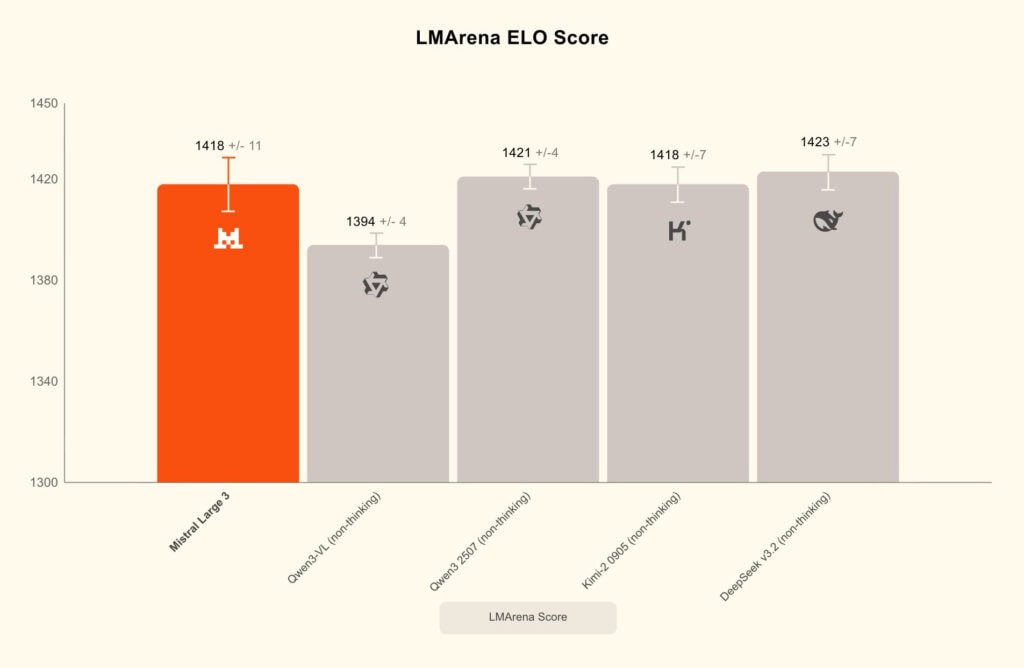
Para muchas empresas, esta combinación de prestaciones altas y licencia abierta es un punto clave. Lo que marca la diferencia es que no hablamos solo de pesos descargables, sino de una política clara de accesibilidad: el compromiso de Mistral AI con modelos abiertos y escalables ha sido uno de los motivos por los que la compañía ha ganado atención tan rápido dentro del ecosistema de IA.
Si tienes prisa por probar Mistral Large 3 sin montar tu propia infraestructura, te interesa saber que los modelos Mistral 3 están disponibles desde el primer momento en varias plataformas. Puedes acceder a ellos a través de Mistral AI Studio para experimentar con prompts, pero también desde servicios de nube bien conocidos como Amazon Bedrock o Azure Foundry.
Además, vas a poder trabajar con Mistral 3 desde Hugging Face, lo que facilita muchísimo el uso de los modelos en pipelines existentes de Python, y desde otros servicios como Modal, IBM WatsonX, OpenRouter, Fireworks, Unsloth AI y Together AI. Esta variedad de puntos de acceso hace que te resulte sencillo probarlos, compararlos con otros modelos y encajarlos en tu stack actual, ya sea desde SDKs propios o desde APIs REST estándar.
Mistral AI ya ha adelantado que va a ir añadiendo más opciones de despliegue para la familia Mistral 3. Eso implica que, si ahora mismo trabajas en otro proveedor o en una plataforma on‑premise concreta, es probable que veas integraciones nuevas a medio plazo, lo que abre aún más el abanico para proyectos empresariales.
Mirando la parte técnica, Mistral Large 3 no se ha entrenado precisamente en pequeño. El modelo ha pasado por un entrenamiento masivo sobre unas 3.000 GPUs NVIDIA H200, una tarjeta pensada específicamente para cargas de trabajo de IA de gran tamaño. Esta cifra da una idea de la escala de datos y cómputo que hay detrás del modelo que luego tú vas a usar con una simple llamada a la API.
En cuanto al diseño interno, Mistral Large 3 incorpora kernels de atención Blackwell y kernels específicos para la mezcla de expertos. Estos componentes están pensados para exprimir mejor el hardware de NVIDIA durante la inferencia y el entrenamiento, reduciendo latencias y mejorando el rendimiento por vatio. Dicho de otra forma, puedes servir más peticiones con la misma GPU o mantener tiempos de respuesta bajos sin tener que sobredimensionar la infraestructura.
Si trabajas en Europa o en contextos con varios idiomas, la parte multilingüe es clave. Mistral Large 3 destaca por unas altas capacidades multilingües, lo que se traduce en mejor comprensión y generación de texto en diferentes lenguas, incluido el español. Para casos de uso empresariales, esto permite montar asistentes que cambian de idioma según el usuario sin tener que duplicar modelos.
Además, el modelo se ha diseñado con fuertes capacidades multimodales. Esto significa que no se limita a texto plano, sino que puede trabajar con entradas visuales. Esa combinación de texto e imagen encaja muy bien con escenarios como análisis de documentos escaneados, soporte técnico con capturas de pantalla o clasificación de imágenes acompañadas de descripciones breves.
Más allá del modelo grande, la llamada serie Ministral 3 está planteada como un conjunto de modelos que vas a poder escalar en distintas capas de tu infraestructura. Está pensada para funcionar tanto en dispositivos en el edge como en centros de datos, lo que te permite acercar la inferencia al usuario cuando lo necesitas y mantener otros flujos pesados en la nube o en servidores locales.
Esta escalabilidad no es solo una frase bonita en la nota de prensa: tener versiones de 3B, 8B y 14B, junto con el propio Mistral Large 3, hace que puedas distribuir la carga. Por ejemplo, puedes reservar el modelo grande para tareas de razonamiento complejo o análisis estratégico y dejar los modelos compactos para clasificación rápida, asistentes ligeros o tareas de etiquetado automático.
Dentro de la serie Ministral 3 te vas a encontrar tres grandes tipos de variantes: base, instruct y reasoning. Las variantes base suelen ser ideales para quienes quieren afinar el modelo con sus propios datos, ya que parten de una red entrenada en general, pero sin un alineamiento fuerte a instrucciones específicas.
Las variantes instruct están más adaptadas a seguir órdenes en lenguaje natural. Si quieres montar un asistente conversacional, un chatbot interno o una herramienta de soporte, estos modelos suelen funcionar mejor “de serie” con prompts sencillos. Por su parte, las variantes reasoning se centran en mejorar el razonamiento en cadenas de pasos, lo que viene muy bien para resolver problemas lógicos, tareas matemáticas o flujos de decisión complejos en entornos empresariales.
Una característica llamativa de la serie Ministral 3 es que todas las variantes admiten comprensión de imágenes. No tienes que irte a un modelo específico o cambiar de API para trabajar con contenidos visuales: tanto en base, como en instruct o reasoning, vas a poder enviar imágenes y obtener análisis, descripciones o respuestas que tienen en cuenta lo que aparece en ellas.
Esta uniformidad facilita mucho el diseño de productos. Puedes comenzar con un modelo instruct para un asistente que responde a texto, y más adelante añadir funciones de subida de imágenes sin cambiar por completo el backend. Para workflows de empresa, como control de calidad visual, análisis de documentos o soporte con fotos, esta compatibilidad común reduce bastante la complejidad técnica.
A la hora de elegir un modelo de lenguaje para tu empresa, la relación coste-rendimiento suele ser el factor decisivo. Según la propia descripción del lanzamiento, los modelos Ministral 3 ofrecen una relación coste-rendimiento fuerte, lo que se traduce en más tokens procesados por euro y en la posibilidad de usar modelos avanzados sin disparar la factura de la nube.
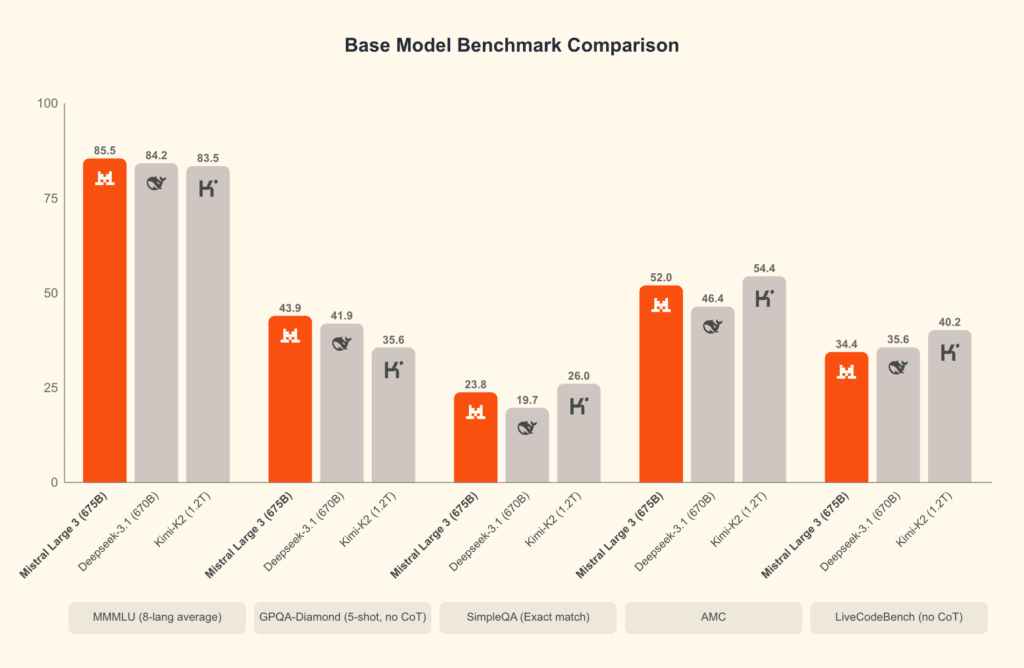
Esta eficiencia tiene impacto directo en cómo diseñas tus flujos: puedes permitir prompts más largos, mantener más contexto en las conversaciones o ejecutar más procesos en paralelo sin que el presupuesto se descontrole. Como siempre, te tocará comparar precios concretos en el proveedor que elijas, pero la orientación de Mistral AI va claramente hacia un uso intensivo en empresa, no sólo hacia demos espectaculares.
Si estás en el lado más técnico y quieres desplegar Mistral Large 3 o los modelos Mistral 3 en tu propia infraestructura, te interesa el formato en el que se distribuyen. Los modelos se entregan en formato NVFP4, un tipo de cuantización diseñado para aprovechar mejor las GPUs modernas de NVIDIA en inferencia.
Este formato NVFP4 está especialmente optimizado para el motor vLLM y para hardware de NVIDIA. ¿Qué implica esto? Que vas a poder obtener más rendimiento con menos memoria, lo que es clave si trabajas con varias instancias de modelo o con tarjetas de gama media. Necesitarás adaptar algo tu stack si vienes de formatos más clásicos, como FP16 puro, pero las ganancias en throughput pueden compensar el esfuerzo.
Gracias a las optimizaciones de formato y a la arquitectura de mezcla de expertos, la inferencia con los modelos Mistral 3 está pensada para ser eficiente en una amplia gama de GPUs. No se trata sólo de grandes H100 o H200, sino también de tarjetas más modestas que puedes tener en servidores propios o incluso en estaciones de trabajo.
Con todo, uno de los puntos más interesantes es la capacidad de desplegar estos modelos en dispositivos en el edge. Poder acercar la inferencia a fábricas, tiendas físicas o estaciones de trabajo remotas reduce la latencia y mejora la privacidad de los datos, algo muy apreciado en sectores como sanidad, industria o retail, donde no siempre quieres enviar toda la información a la nube.
Detrás de Mistral Large 3 está Mistral AI, una empresa francesa enfocada en soluciones de IA abiertas y escalables. Este posicionamiento no es sólo marketing: desde sus primeros modelos han apostado por pesos abiertos y licencias permisivas, lo que ha creado una comunidad activa alrededor de sus lanzamientos.

En muy poco tiempo, Mistral AI ha ganado atención en el sector precisamente por este compromiso con la accesibilidad de sus modelos. Para ti, como desarrollador o responsable técnico, esto se traduce en más control, más capacidad de auditoría y la opción de adaptar los modelos a tu realidad sin depender por completo de APIs cerradas.
Otro punto que influye en la calidad técnica de la familia Mistral 3 es el ecosistema de colaboradores. La empresa trabaja estrechamente con NVIDIA, Red Hat y el proyecto vLLM para afinar tanto el entrenamiento como el despliegue de sus modelos, lo que mejora la integración en entornos reales.
Estas colaboraciones se notan en detalles como el soporte para drivers y librerías actualizadas, la compatibilidad con plataformas de contenedores empresariales o las mejoras en los motores de inferencia. Si gestionas infraestructuras complejas, agradeces bastante que el proveedor de modelos se haya coordinado antes con quienes construyen el hardware y el software de base.
Las primeras reacciones de la industria al lanzamiento de Mistral Large 3 y la familia Mistral 3 han hecho énfasis en un punto muy concreto: la publicación de pesos abiertos. En un contexto donde muchos modelos punteros son cerrados o aplican licencias restrictivas, disponer de pesos abiertos con calidad competitiva se ve como algo especialmente valioso.
Para empresas y desarrolladores, esto supone una ventaja doble. Por un lado, puedes auditar mejor cómo se comporta el modelo y evaluar riesgos. Por otro, puedes afinar el modelo con tus propios datos, desplegarlo en tus servidores y controlarlo de extremo a extremo sin depender de cambios unilaterales en una API externa.
Uno de los motivos por los que Mistral 3 está despertando interés entre desarrolladores y organizaciones es su capacidad de adaptación a flujos de trabajo muy distintos. Gracias a los pesos abiertos y a la variedad de variantes (base, instruct, reasoning), vas a poder integrar estos modelos en pipelines específicos sin obligarte a cambiar tus herramientas principales.
La industria está viendo esta flexibilidad como un factor diferencial. Puedes montar desde sistemas de revisión de código, asistentes jurídicos, analizadores de logs o generadores de informes financieros, ajustando prompts, añadiendo capas de post-procesado o afinando el modelo con ejemplos propios. Todo ello se apoya en la combinación de licencia Apache 2.0, buen rendimiento y facilidad de despliegue en nubes públicas, centros de datos o entornos en el edge.
Si juntamos todas estas piezas, Mistral Large 3 y la familia Mistral 3 se colocan como una opción muy seria para cualquiera que quiera modelos de IA abiertos, con soporte multilingüe sólido, capacidades multimodales y una buena relación coste-rendimiento. Tanto si buscas un modelo grande de 41.000 millones de parámetros activos para tareas complejas como si necesitas variantes más compactas para el edge, vas a poder construir soluciones a medida, sin quedarte atado a un único proveedor cerrado.
Me dedico al SEO y la monetización con proyectos propios desde 2019. Un friki de las nuevas tecnologías desde que tengo uso de razón.
Estoy loco por la Inteligencia Artificial y la automatización.

La Newsletter Diaria Sobre Inteligencia Artificial. Además: Portal de Noticias, Tutoriales, Tips y Trucos de ChatGpt, Openai e Inteligencia Artificial.
Nuestra web está alojada en:


