El hallazgo que circula en torno a ChatGPT, incluso en versiones nuevas como GPT‑5.2, es tan simple como incómodo: ante la pregunta “¿cuántas ‘r’ hay en la palabra ‘strawberry’?”, el sistema suele responder “dos”. Y lo hace con una confianza que suena a certeza humana.
Sin embargo, la palabra “strawberry” tiene tres “r”. Y esa grieta, que se observa desde el lanzamiento de ChatGPT en 2022 y persiste en modelos posteriores como GPT‑4o y GPT‑5.2, revela una pieza clave: no es un descuido menor, sino un mecanismo profundo de cómo funcionan los modelos de lenguaje (LLM, “modelos que completan texto”).
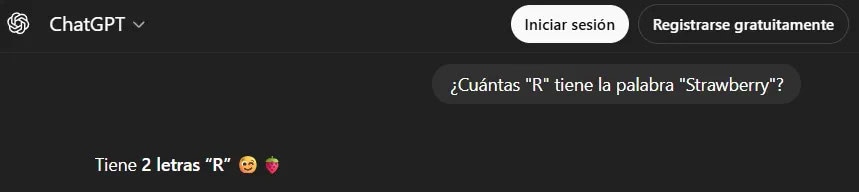
Porque el problema no es “falta de inteligencia” en el sentido común. Es, más bien, un tema de cableado interno. La central de este fallo está en la tokenización (segmentación del texto en fragmentos), el sistema con el que el modelo “ve” lo que le escribís.
Para entenderlo, sirve una analogía doméstica: ChatGPT no lee letras como si fueran granos de arroz; lee “paquetes” como si fueran bolsas ya armadas. Si le pedís contar granos dentro de una bolsa cerrada, puede adivinar. Pero no está mirando uno por uno.
En los LLM, esos “paquetes” se llaman tokens (pedazos de texto). Un token puede ser una palabra completa, una sílaba o un trozo de palabra, según el vocabulario del modelo. Y ese engranaje es eficiente para escribir, traducir o resumir. Pero se vuelve frágil para tareas de “microscopio”, como contar letras.
El contraste es el que más desconcierta: mientras la industria invierte miles de millones y el hardware se vuelve más caro (componentes como la RAM, memoria de trabajo, son parte del costo), la IA falla en una consigna que un chico puede resolver sin esfuerzo.
También te puede interesar:OpenAI Añade un Carrito de Compra Y Herramientas para Comercios dentro de ChatGPT
Además, el texto subraya que este límite podría no corregirse del todo mientras se mantenga el paradigma actual. Aunque OpenAI cambió y ajustó tokenizadores —por ejemplo, con “o200k_harmony” (un vocabulario de tokens más amplio) usado en GPT‑4o y GPT‑5—, el caso “strawberry” sigue encendiendo el mismo interruptor de error.
Y no es la primera vez que los tokens generan comportamientos extraños. Hubo cadenas famosas como “solidgoldmagikarp”, que en GPT‑3 funcionaban como un exploit (una entrada que desacomoda el sistema): podían disparar insultos, texto ilegible o bucles lógicos. Con el tiempo, OpenAI aplicó parches para mitigar esos tokens conflictivos.
Esta historia deja una regla útil para la vida diaria: si la tarea requiere manipular letras, números o símbolos con precisión, conviene chequear. Especialmente en contraseñas, códigos, conteos, transcripciones exactas o datos que después vas a copiar y pegar.
En cambio, para redactar, ordenar ideas o explicar temas complejos, el sistema suele ser sólido. Ahí el mecanismo de predicción (anticipar qué token sigue) juega a favor y se siente casi como una conversación.
La oportunidad, entonces, no es pedirle a la IA que sea una calculadora de letras, sino usarla como lo que es: una máquina muy buena para patrones de lenguaje. Y, cuando haga falta precisión quirúrgica, sumar el gesto humano más antiguo del mundo digital: mirar dos veces.
También te puede interesar:OpenAI Usa IA y Selfies para Blindar ChatGPT a Menores: Cómo Afecta a Tu Privacidad y a Tus Datos
Directora de operaciones en GptZone. IT, especializada en inteligencia artificial. Me apasiona el desarrollo de soluciones tecnológicas y disfruto compartiendo mi conocimiento a través de contenido educativo. Desde GptZone, mi enfoque está en ayudar a empresas y profesionales a integrar la IA en sus procesos de forma accesible y práctica, siempre buscando simplificar lo complejo para que cualquiera pueda aprovechar el potencial de la tecnología.

La Newsletter Diaria Sobre Inteligencia Artificial. Además: Portal de Noticias, Tutoriales, Tips y Trucos de ChatGpt, Openai e Inteligencia Artificial.
Nuestra web está alojada en:


