Kling AI está calentando motores para su “era 3.0” con el lanzamiento de Kling VIDEO 3.0, un modelo unificado de vídeo que, por ahora, solo unos pocos usuarios pueden probar en fase de previsualización. La propuesta no apunta a ser simplemente “un modelo un poco mejor”, sino algo mucho más ambicioso: convertirse en una especie de sistema operativo de vídeo, donde generar, dirigir y ajustar contenidos sin tener que saltar constantemente entre herramientas.
La idea central es reunir en un mismo marco nativo de entrenamiento multimodal todo el ecosistema creativo, desde texto-a-vídeo, imagen-a-vídeo, generación por referencias y modificación directa de vídeo. Esto se traduce en menos procesos fragmentados, menos “pipeline Frankenstein” y una creación de principio a fin dentro de un solo entorno de trabajo.
Sin embargo, el entusiasmo inicial suele chocar con un problema clásico del vídeo generativo: lo visualmente atractivo aguanta apenas unos segundos antes de perder coherencia. Personajes que mutan, escenas que se vuelven inestables y narrativas que se desmoronan. Justo ahí es donde Kling asegura estar poniendo el foco, atacando aspectos clave como duración, consistencia, control por plano y audio integrado.
El modelo se presenta como una consolidación de lo ya visto en VIDEO 2.6 y en la línea anterior VIDEO 01, ahora unificados dentro de una sola familia. Esta integración busca resolver la fragmentación habitual de usar “un modelo para X y otro para Y”, algo que en el día a día se traduce en estilos inconsistentes, límites variables y prompts ajustados una y otra vez como si se tratara de un benchmark interminable.
Uno de los avances más fáciles de entender es la duración: hasta 15 segundos en una sola generación. No se trata solo de sumar segundos, sino de permitir pequeños beats narrativos sin dividir el vídeo en múltiples clips de tres segundos que luego deben unirse manualmente. A esto se añade un control flexible de duración entre 3 y 15 segundos, pensado para ajustar el ritmo sin necesidad de regenerar contenido por exceso o defecto de tiempo.
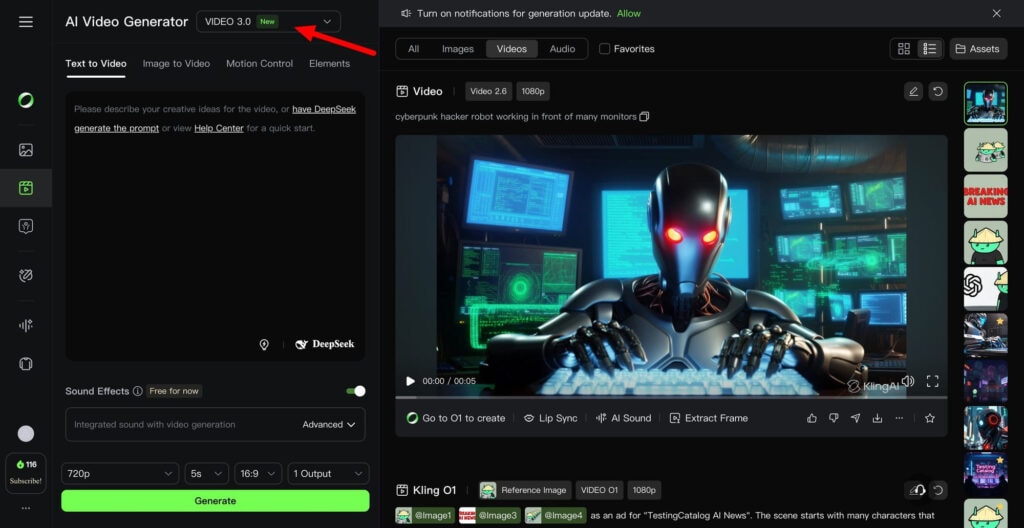
Claro está, la duración por sí sola no resuelve nada si el sistema no entiende continuidad de escena, lenguaje de cámara y consistencia del sujeto, y ahí entra uno de los pilares más interesantes del modelo.
También te puede interesar:Kling AI revoluciona la generación de videos con su función "Elements" para fusionar imágenesUna de las funciones estrella anticipadas para VIDEO 3.0 es Multi-Shot, concebida como un flujo de storyboard inteligente. La propuesta es que el modelo interprete el prompt como una cobertura de escena, reconociendo patrones de planos y ajustando automáticamente ángulos de cámara y composición.
La diferencia clave es que ya no se busca generar “un vídeo” aislado, sino una secuencia con intención de dirección. Kling plantea desde configuraciones básicas, como el clásico plano-contraplano en un diálogo, hasta secuencias más complejas con múltiples planos encadenados. El listón aquí es alto, porque si Multi-Shot realmente reduce la necesidad de cortar y montar manualmente, el impacto no es cosmético, sino un cambio real en el flujo de trabajo creativo.
El objetivo declarado es obtener resultados más cinematográficos en una sola pasada, sin depender de un NLE para corregirlo todo a base de edición manual. A esto se suman controles de plano más granulares dentro del storyboard, como duración, tamaño de plano, perspectiva, contenido narrativo y movimiento de cámara por toma. El resultado apunta a un punto intermedio entre el prompting puro, demasiado vago, y la edición profesional completa, excesivamente lenta para prototipar ideas.
Cualquiera que haya trabajado en serio con vídeo generativo conoce el mayor punto de ruptura: cuando el sujeto deja de ser el mismo. Cambios de rostro, vestuario o incluso de especie rompen la ilusión en segundos. Kling afirma que VIDEO 3.0 mejora de forma notable la consistencia del sujeto, especialmente en flujos de imagen-a-vídeo y en aquellos guiados por referencias.
El sistema intenta fijar elementos nucleares del personaje o la escena para evitar que se deshagan con el movimiento de cámara o con el paso del tiempo dentro del clip. A esto se añade soporte para múltiples imágenes de referencia y también referencias en vídeo, agrupadas bajo el concepto de Elements. Estos funcionan como anclas reutilizables: assets de personajes o escenarios que pueden recombinarse en nuevas generaciones para mantener continuidad.
Más allá de la comodidad, este enfoque marca la diferencia entre simples clips vistosos y un flujo de producción real, donde la coherencia entre escenas es imprescindible.
VIDEO 3.0 Omni se posiciona como la variante más orientada al trabajo con referencias. Según Kling, mejora la consistencia del sujeto, la adherencia al prompt y la estabilidad frente a su modelo anterior enfocado en referencias. El flujo propuesto es directo: se sube un clip corto del personaje para extraer rasgos visuales y, de forma opcional, un clip de voz para capturar características vocales.
De esta manera, se construye una biblioteca propia de Elements que puede reutilizarse escena tras escena, reduciendo la dependencia de la aleatoriedad del modelo y reforzando la identidad del personaje a lo largo del tiempo.
El audio se presenta como uno de los pilares del lanzamiento, con una mejora del audio nativo que incluye referenciado de voz por personaje. En escenas con varios interlocutores, uno de los problemas habituales es la ambigüedad sobre quién habla o cómo se reparte la voz entre los rostros. La promesa aquí es clara: indicar qué personaje habla y que el sistema lo respete.
A esto se suma un soporte multilingüe ampliado, con mención explícita de inglés, chino, japonés, coreano y español. Más allá del número de idiomas, lo interesante es la posibilidad de escenas bilingües o multilingües manteniendo coherencia entre diálogo y movimiento de labios.
También se menciona una salida de texto a nivel nativo para lograr rotulación precisa y legible. Esto incluye carteles, señalética, subtítulos y composiciones publicitarias que no parezcan jeroglíficos, uno de los grandes tropiezos de muchos modelos actuales. Si esta promesa se cumple, Kling se acerca claramente a un uso comercial y de marketing, no solo a la creación de clips estilizados para redes sociales.

El mensaje de fondo es contundente: buscan que el creador obtenga secuencias más largas, coherentes, con personajes estables y sonido integrado, reduciendo al mínimo los pasos externos. Aun así, queda la incógnita habitual: la disponibilidad. Por ahora, Kling habla de un lanzamiento próximo, con acceso limitado en previsualización y una apertura más amplia más adelante.
Habrá que ver si, cuando llegue a todo el mundo, mantiene esa promesa de “control sin pipeline complejo”. Si Multi-Shot y los Elements funcionan como se anticipa, esto podría ser solo el inicio de una nueva forma de dirigir vídeo con IA.
Me dedico al SEO y la monetización con proyectos propios desde 2019. Un friki de las nuevas tecnologías desde que tengo uso de razón.
Estoy loco por la Inteligencia Artificial y la automatización.

La Newsletter Diaria Sobre Inteligencia Artificial. Además: Portal de Noticias, Tutoriales, Tips y Trucos de ChatGpt, Openai e Inteligencia Artificial.
Nuestra web está alojada en:


