Google ha frenado una campaña bastante seria para clonar Gemini usando su propia API oficial, y lo más llamativo no es solo la intención, sino el volumen: más de 100.000 prompts lanzados de forma sistemática. No estamos ante el típico intento de tumbar un servicio mediante saturación o forzar una caída por sobrecarga, sino frente a algo mucho más fino y estratégico: copiar cómo piensa y responde el modelo para construir un rival desde fuera.
Según lo publicado por Android Headlines, los atacantes habrían enviado más de 100.000 consultas con estilos, temáticas y formulaciones distintas para mapear el comportamiento del chatbot. Es decir, no se trataba de preguntas aleatorias, sino de un proceso metódico cuyo objetivo era observar patrones, límites, decisiones de formato y reacciones ante distintos tipos de estímulos.
Ahora bien, la jugada no consistía en entrar a los servidores de Google ni en robar los pesos del modelo como si fuese una película de hackers. El enfoque era mucho más elegante y, en cierto modo, más inquietante: extraer patrones de razonamiento internos a partir de las respuestas públicas, y con esa información entrenar otro sistema que se “comporte” como Gemini sin haber asumido el coste brutal de entrenarlo desde cero.
La palabra clave de toda esta historia es destilación, una técnica perfectamente legítima dentro del machine learning cuando se utiliza con permiso y bajo marcos contractuales claros, pero extremadamente delicada cuando se convierte en una vía indirecta de copia. En términos simples, la destilación consiste en usar un “modelo profesor” —en este caso, Gemini— para generar respuestas y luego entrenar un “modelo estudiante” a imitar esas salidas.
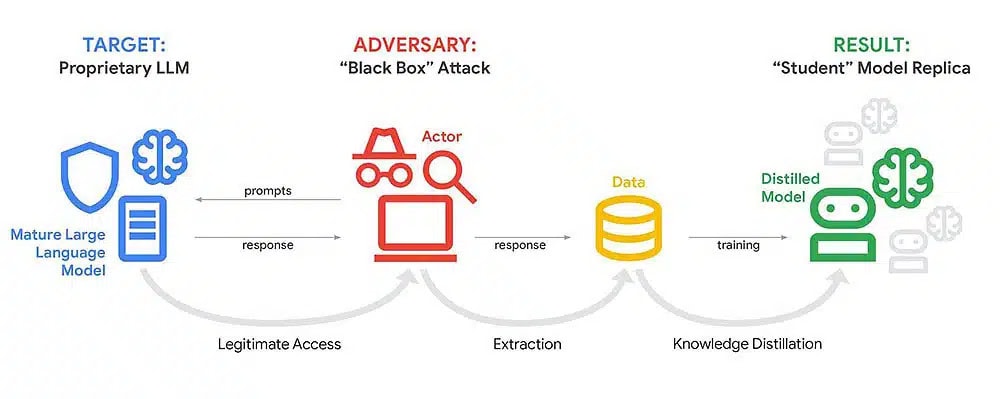
Dicho de otro modo, si no puedes o no quieres pagar el coste astronómico de entrenar un LLM desde cero, puedes intentar aprender su comportamiento observándolo por fuera, como quien copia en un examen mirando la hoja del compañero. La diferencia es que aquí no se trata de una mirada ocasional, sino de un proceso automatizado y masivo que recopila miles de ejemplos cuidadosamente diseñados.
A ello se suma un matiz importante: este tipo de ataque no busca reproducir exactamente los parámetros internos del modelo, algo que sería prácticamente imposible sin acceso directo, sino replicar su comportamiento observable en miles de situaciones. Y si el dataset de “pregunta-respuesta” es lo suficientemente grande y está bien diseñado, el resultado puede ir mucho más allá de una copia superficial. Puede terminar siendo un modelo que “da el pego” en prompts típicos, que reproduce el mismo tono, las mismas decisiones de estructura e incluso ciertas manías al razonar.
También te puede interesar:Función ‘Ask Gemini’ en Google Meet: Resume Todo lo que ha Pasado en la VideollamadaEn ese punto, ya no hablamos de una imitación burda, sino de una aproximación funcional al producto original. Y cuando lo que se copia no son datos en bruto, sino criterios y estilos de decisión, lo que se está replicando es el valor central del sistema.
Lo más inquietante de todo no es solo la técnica, sino el vector de entrada. El ataque se habría basado en abusar del acceso a la API que Google ofrece a desarrolladores. Es decir, no hizo falta comprometer infraestructuras complejas ni vulnerar sistemas internos; bastó con tener acceso legítimo y automatizar un pipeline de consultas.
Esto cambia la naturaleza del problema. La seguridad ya no consiste únicamente en bloquear intrusiones externas, sino en detectar patrones de uso que revelan una extracción sistemática de conocimiento. Desde el punto de vista del atacante, el enfoque es casi perfecto: es relativamente barato, escalable y se apoya en un canal oficial.

Además, muchos equipos utilizan APIs de modelos para prototipos, evaluación o generación de datos sintéticos, lo que genera un volumen de tráfico legítimo considerable. En ese contexto, distinguir entre uso normal y comportamiento malicioso no es trivial. Separar el ruido de la señal exige sistemas de monitorización sofisticados y análisis de comportamiento avanzados.
Y aunque 100.000 prompts puedan parecer muchos para un titular, en términos prácticos no representan una barrera inalcanzable para un equipo con presupuesto medio y cierta disciplina técnica. De hecho, si el acceso está bien automatizado y distribuido en el tiempo, el patrón puede pasar desapercibido durante bastante tiempo.
La cifra no es solo impactante desde el punto de vista mediático; es significativa desde el punto de vista técnico. Cien mil ejemplos bien diseñados permiten cubrir estilos de escritura, tareas diversas —código, resumen, razonamiento, clasificación—, múltiples idiomas y tonos, e incluso incluir “trampas” para observar cómo el modelo se corrige o cómo se niega ante determinados contenidos.
También te puede interesar:Sin Fotógrafo ni Estudio: Crea Fotos Profesionales Gratis, con Google Gemini
No se trata de repetir la misma pregunta miles de veces. El verdadero valor está en diseñar prompts que estresen los límites: ambigüedades, instrucciones contradictorias, cambios de rol, cadenas de razonamiento largas, variaciones mínimas que obliguen al modelo a mostrar sus criterios internos. A través de ese proceso, es posible inferir decisiones estructurales sin tener acceso directo a ellas.
Ahí radica la clave: no se copian datos sin procesar, se copian criterios de decisión. Y copiar criterios es, en esencia, copiar producto. Porque en modelos de lenguaje avanzados, el valor diferencial no está únicamente en el volumen de datos o en el tamaño de la arquitectura, sino en cómo el sistema decide responder ante contextos complejos.
Este episodio refleja algo que muchos en la industria ya asumen en voz baja: el valor competitivo no reside únicamente en lanzar el LLM más grande o con más parámetros, sino en proteger sus secretos operativos. Si un competidor puede aproximarse a tus capacidades mediante destilación a gran escala, tu ventaja tecnológica puede reducirse sin que nadie haya tocado tu hardware ni tus servidores internos.
En ese escenario, la competencia se transforma en una carrera armamentística donde quien mejor protege y monitoriza su API puede tener tanto peso estratégico como quien mejor entrena su modelo. Sin embargo, cerrar demasiado el acceso también tiene un coste evidente: menos desarrolladores, menos integraciones, menor adopción y, en consecuencia, un ecosistema más débil.
Se abre así un dilema incómodo. La misma apertura que acelera la adopción real de la IA y multiplica sus casos de uso es la que puede facilitar el copiado cuando se automatiza y se industrializa. Es un equilibrio delicado entre fomentar innovación y proteger propiedad intelectual.
Google afirma haber detectado y frenado la campaña, lo que sugiere que existen sistemas de monitorización y límites diseñados específicamente para identificar este tipo de patrones. Pero si ofreces una API pública a escala global, el abuso no es una posibilidad remota; es prácticamente una certeza estadística. La cuestión no es si alguien lo intentará, sino cuándo y con qué nivel de sofisticación.
Lo que veremos a partir de ahora es hasta qué punto las grandes compañías endurecen controles, límites de uso, verificación de identidad y análisis conductual para frenar esta forma encubierta de destilación. Porque, en el fondo, esto podría ser apenas el comienzo de una guerra silenciosa: la de copiar modelos sin hackearlos, simplemente hablándoles miles de veces… y tomando notas con paciencia industrial.
Me dedico al SEO y la monetización con proyectos propios desde 2019. Un friki de las nuevas tecnologías desde que tengo uso de razón.
Estoy loco por la Inteligencia Artificial y la automatización.

La Newsletter Diaria Sobre Inteligencia Artificial. Además: Portal de Noticias, Tutoriales, Tips y Trucos de ChatGpt, Openai e Inteligencia Artificial.
Nuestra web está alojada en:


