

Llevamos meses viendo cómo cada nuevo modelo de lenguaje destroza las métricas de programación, pero a la hora de la verdad, en tu editor de código local, la historia cambia drásticamente. Para pinchar esta burbuja, Cursor acaba de sacar la artillería pesada y ha presentado CursorBench-3, una potente suite de evaluación interna diseñada para medir si los agentes de IA realmente saben programar o solo aprueban exámenes.
Y es que el mercado actual está inundado de promesas exageradas y cifras mareantes. Las herramientas de asistencia suelen brillar en entornos aislados o scripts de pocas líneas, pero tropiezan estrepitosamente cuando les pides que toquen un proyecto de software real. Este benchmark nace exactamente para penalizar eso. Una auténtica locura.
Según detallan los ingenieros en su publicación original, esta nueva iteración evalúa de forma quirúrgica la corrección de las soluciones, la calidad del código, la eficiencia de respuesta y el comportamiento general del agente. Todo ello basándose en interacciones reales sacadas directamente de las sesiones de producción de los desarrolladores. Se acabaron las pruebas de laboratorio estériles.
Las métricas tradicionales han roto el mercado del software
Si miramos los números de los últimos meses, los benchmarks públicos han tocado un techo muy peligroso. Los modelos de frontera están tan optimizados para pasar este tipo de pruebas que la comunidad sospecha de una alta contaminación en sus datos de entrenamiento. Básicamente, la IA se sabe las respuestas del examen de memoria porque ya las ha visto antes en internet.
También te puede interesar:Gestión de Agentes AI en Cursor: Nueva Aplicación Web Para DesarrolladoresComo era de esperar, Cursor considera que estas pruebas clásicas muestran serias limitaciones para medir el rendimiento de los modelos más avanzados. La empresa entiende que no reflejan para nada el día a día de un programador senior que lidia con código heredado o arquitecturas enrevesadas. Por eso han decidido fabricar su propio estándar.
A ello se le suma una táctica muy inteligente para mantener la fiabilidad del sistema. El nuevo benchmark incorpora un bloque de tareas que se actualizan de forma constante utilizando la funcionalidad Cursor Blame. Es decir, inyectan problemas frescos en la base de datos de evaluación para mitigar casi por completo el riesgo de contaminación. Así de simple.
Proyectos gigantes y peticiones ambiguas: el test de estrés definitivo
Seguramente te ha pasado más de una vez: le pides a un agente que te arregle un simple bug visual y de paso te rompe tres archivos del backend que no tenían nada que ver. Las tareas que forman parte de CursorBench-3 tienen un alcance masivo si las comparamos con sus versiones anteriores o con cualquier alternativa pública.
También te puede interesar:Gestión de Agentes AI en Cursor: Nueva Aplicación Web Para DesarrolladoresEn concreto, muchas de estas pruebas obligan a la IA a moverse por proyectos con múltiples archivos y complejos monorepos. Además, enfrentan al modelo a solicitudes totalmente ambiguas o mal explicadas por parte del usuario. En otras palabras, imitan las peticiones desastrosas que cualquier desarrollador humano escribe en el prompt un viernes a última hora cuando ya está cansado.
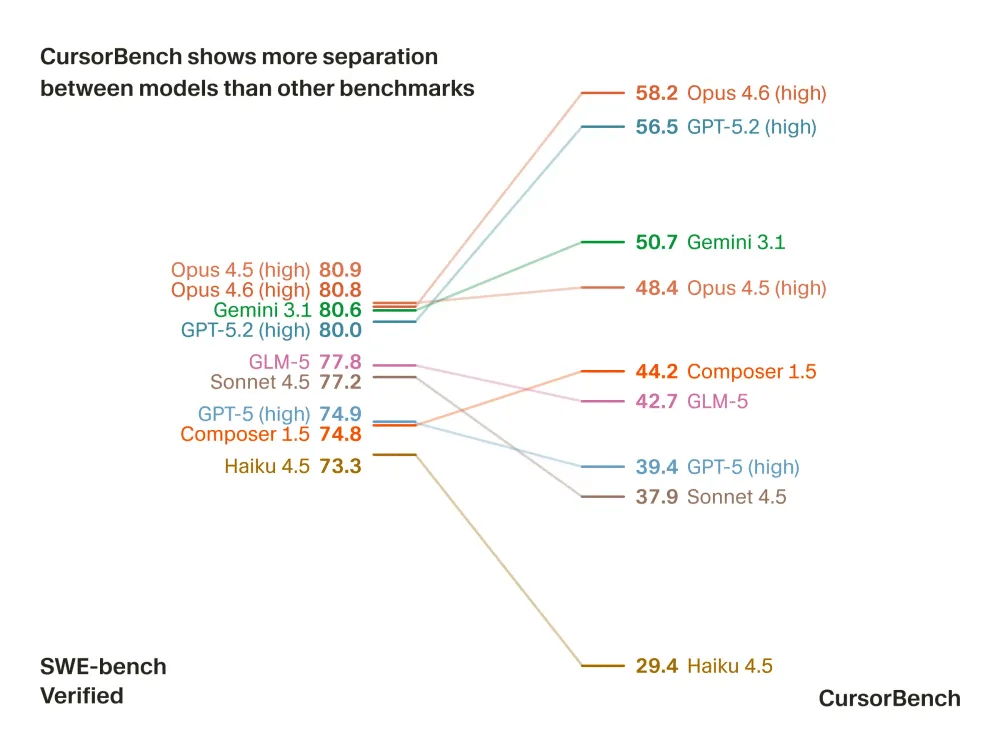
Evidentemente, el objetivo final es comprobar si el agente es capaz de entender el contexto técnico completo de la aplicación y no solo una función aislada. La herramienta obliga a la máquina a sudar la gota gorda, descartando rápidamente a los modelos que solo sirven para generar código básico de principiante.
El salto de las pruebas offline a la satisfacción del desarrollador
La letra pequeña de todo este anuncio es que esta herramienta no está pensada para que tú y yo juguemos con ella. CursorBench-3 está disponible de manera estrictamente interna para sus propios equipos de ingeniería e investigación. Los resultados que escupe esta bestia de evaluación se utilizan directamente para orientar el despliegue de nuevos modelos dentro de su ecosistema.
Pero claro, sacar una nota alta en un test automático no garantiza que el usuario acabe contento con el resultado final. Para tapar esa enorme brecha, la startup complementa todas estas evaluaciones offline con experimentos online altamente controlados. Buscan detectar al milímetro cualquier fricción entre la puntuación automática de la máquina y la satisfacción real del desarrollador que está tecleando.

El lanzamiento de este ecosistema marca una clara estrategia de diferenciación en un sector ultra competitivo. Mientras otros gigantes del software se pelean por anunciar que su último LLM supera el 95% en un test irrelevante, Cursor se desmarca centrando sus recursos operativos en flujos de trabajo reales. No quieren trucos estadísticos.
Al final del día, la asistencia de código impulsada por IA va a seguir aumentando en complejidad, y ya no bastará con un simple autocompletado rápido. Mantener el desarrollo de los agentes estrechamente alineado con las necesidades de los programadores es la única vía de supervivencia en este nicho. La pelota está ahora en el tejado de la competencia para ver si responden con sus propios sistemas o siguen confiando en exámenes que ya nadie se cree.

Me dedico al SEO y la monetización con proyectos propios desde 2019. Un friki de las nuevas tecnologías desde que tengo uso de razón.
Estoy loco por la Inteligencia Artificial y la automatización.







