

¿Te has dado cuenta de que últimamente la carrera de la inteligencia artificial parece tratar solo de quién tiene el modelo más gigantesco? Hablamos de acaparar servidores enteros, claro. La start-up francesa Mistral AI ha decidido bajarse de ese tren del bombo publicitario y acaba de presentar Mistral Small 4. Este nuevo sistema no viene a romper récords de tamaño absurdos, sino a hacer algo mucho más inteligente: ser increíblemente ágil y versátil. Un golpe sobre la mesa.
Y es que la propuesta central de este lanzamiento rompe con la dinámica habitual de tener una herramienta para cada cosa. Hasta ahora, si querías generar código usabas una versión, si querías analizar imágenes otra, y si buscabas razonamiento complejo, una tercera. Ahora la compañía ha metido en una coctelera las capacidades de Magistral, Pixtral, Devstral y su propia serie Small anterior. El resultado es un único sistema unificado. Así de simple.
Básicamente, la idea de los franceses es que dejes de volverte loco saltando entre modelos especializados según la tarea que toque. Esto está pensado para hacerle la vida mucho más fácil tanto a desarrolladores que exploran código, como a empresas que necesitan montar asistentes conversacionales rápidos. Tener un modelo «todo en uno» recorta drásticamente la complejidad técnica de los flujos de trabajo de cualquier start-up. Menos dolores de cabeza.
El truco de la arquitectura: 119.000 millones de parámetros engañosos
Si miramos los números puros, nos topamos con unas especificaciones que imponen bastante respeto. El nuevo modelo utiliza una arquitectura conocida en la industria como Mixture of Experts (MoE), albergando concretamente 128 expertos bajo el capó. Sin embargo, la magia de este diseño radica en que solo cuatro de esos expertos participan de forma simultánea en la generación de cada token. No necesitas despertar a toda la bestia para responder una consulta rutinaria.
También te puede interesar:Mistral Presenta su Herramienta Forge para Entrenar Modelos de IA Empresariales con Datos PropiosEn concreto, estamos hablando de un tamaño total de 119.000 millones de parámetros en el modelo completo, pero que a la hora de la verdad solo mantiene unos 6.000 millones activos por token generado. A esto se le suma una monstruosa ventana de contexto de 256.000 tokens, lo que te permite volcar libros enteros o bases de código kilométricas sin que el sistema sude una gota. Es decir, tienes la potencia de un gigante cuando la necesitas, pero consumiendo la energía de un modelo ultracompacto. Una auténtica locura.
Hablar menos para rendir más
Pero claro, los números técnicos no significan nada si luego la IA es incapaz de dar respuestas precisas. En los test de rendimiento, como el exigente benchmark AA LCR, Small 4 obtiene una puntuación de 0,72. Y aquí viene lo interesante del asunto: no lidera la tabla de clasificación, ya que modelos de la competencia como Qwen3.5 122B (0,84) o Claude Haiku (0,80) sacan mejores notas globales. Podría parecer una derrota sobre el papel. No lo es.
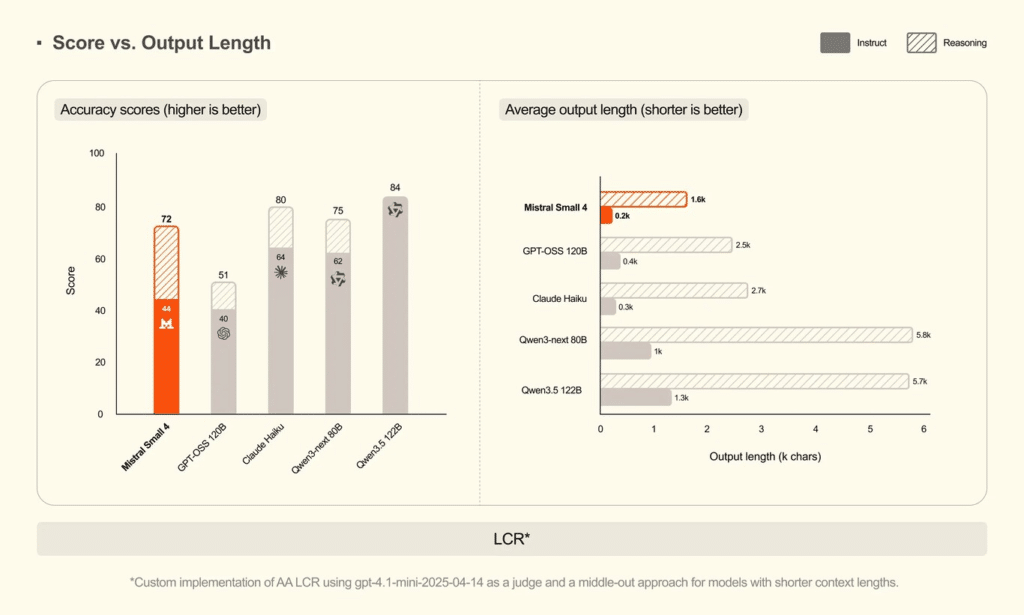
El motivo de esta aparente desventaja esconde la verdadera fortaleza de la IA europea: sus respuestas tienen una media de solo 1.600 caracteres. Si lo comparamos con el resto, vemos que un modelo como GPT-OSS 120B saca un pobre 0,51 requiriendo 2.500 caracteres, Claude Haiku necesita unos 2.700 y la versión Qwen3-next 80B roza los 5.800 caracteres para resolver lo mismo. Small 4 es directo, va al grano y no te suelta un rollo insufrible para justificar su existencia. Generar menos texto manteniendo una calidad alta es el verdadero tesoro.
También te puede interesar:Mistral Presenta su Herramienta Forge para Entrenar Modelos de IA Empresariales con Datos PropiosComo era de esperar, esta brevedad intencionada tiene un impacto brutal en el bolsillo de quien despliega el modelo en el mundo real. Escribir menos caracteres significa disfrutar de una menor latencia y, sobre todo, una reducción drástica en el coste de inferencia. Si estás integrando esto en una aplicación para el móvil que recibe cientos de miles de consultas diarias, te haces una idea del tremendo ahorro económico que supone. La eficiencia manda.
Acceso total y espíritu open-source
Por si fuera poco, Mistral sigue fiel a su filosofía de no cerrar el ecosistema bajo llave, algo que la comunidad agradece enormemente. El nuevo modelo ya se puede exprimir a través de la API oficial de la compañía para integrarlo en proyectos externos. Además, está disponible de forma nativa en su plataforma para desarrolladores AI Studio.
Evidentemente, al distribuirse bajo una licencia Apache 2.0, estamos ante una inteligencia artificial de código abierto. Puedes descargar los pesos, ajustarlo a tus necesidades más extrañas y montarlo en los servidores locales de tu empresa o en tu propio ordenador sin pagar peajes. Si prefieres trastear un poco antes de instalar nada, la compañía permite probarlo gratis en build.nvidia.com y usarlo directamente en producción apoyado por la infraestructura escalable de NVIDIA NIM.
La estrategia de la empresa europea está muy clara: abandonar la guerra por el modelo más mastodóntico y centrarse en ofrecer herramientas rentables, rápidas y que realmente solucionen problemas. Veremos cómo responde la gran competencia estadounidense ante esta obsesión francesa por la optimización extrema. De momento, la pelota está en el tejado de los desarrolladores, que serán quienes dicten sentencia sobre este nuevo estándar.

Me dedico al SEO y la monetización con proyectos propios desde 2019. Un friki de las nuevas tecnologías desde que tengo uso de razón.
Estoy loco por la Inteligencia Artificial y la automatización.









