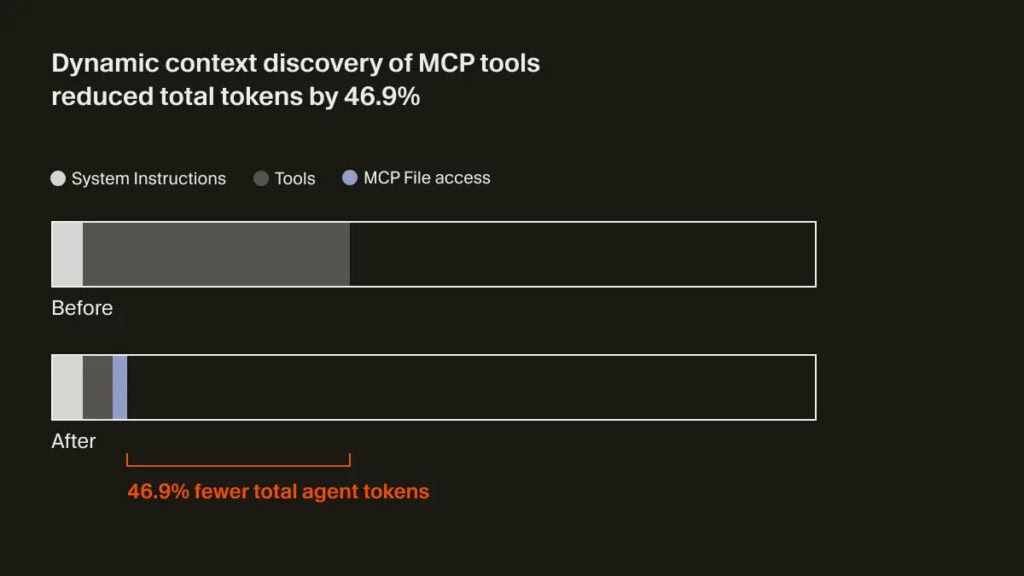
Cursor acaba de meter mano a uno de los cuellos de botella más aburridos —y más caros— de los agentes de programación: el contexto. Su nuevo sistema de dynamic context discovery promete algo muy concreto: en una prueba interna A/B, el uso de tokens cayó un 46,9% cuando el agente trabajaba con herramientas MCP.
Si llevas tiempo jugando con agentes dentro de un IDE, el problema te resulta familiar. Todo va fino… hasta que el agente empieza a tragarse logs, outputs interminables y chat histórico como si no hubiese mañana. Eso no solo dispara el consumo de tokens, sino que aumenta el riesgo de perder justo la información importante por culpa del context bloat.
El cambio clave es casi conceptual. En lugar de volcar enormes respuestas de herramientas —por ejemplo, salidas largas de comandos de terminal— directamente en el contexto del agente, Cursor ahora guarda esos datos como ficheros. Y es que el contexto del LLM no es un disco duro; es una mochila con límite, y cada línea de ruido roba espacio al razonamiento.
También se guarda como archivo el historial de chat, además de otras piezas del flujo de trabajo que antes se “pegaban” sin filtro en la conversación. El agente deja de cargarlo todo por defecto y pasa a operar como lo haría un desarrollador humano: si necesito un detalle, lo busco.
Aquí entra el matiz importante. El agente recupera solo lo necesario bajo demanda, usando comandos como tail o grep. En vez de meter 5.000 líneas de salida de un build fallido, extrae las 30 relevantes donde aparece el error. Menos ruido, más señal.
Cursor afirma que este enfoque “permite un uso más eficiente de tokens y minimiza la pérdida de información”. Pero esto no va solo de pagar menos inferencia. Va de que el agente mantenga el hilo cuando el proyecto se complica.
También te puede interesar:Cursor 2.4 Trae Novedades en Subagentes Autónomos y Generación de ImágenesCuando el contexto está saturado, el modelo toma atajos, se contradice o empieza a repetir pasos como un loro con resaca. El dynamic context discovery convierte el contexto en un índice operativo: el LLM razona con un resumen y tira del archivo solo cuando necesita pruebas.

Esto encaja con una realidad incómoda: los agentes útiles no viven en prompts elegantes, viven en pipelines con terminal, tests, dependencias y herramientas externas. Precisamente ahí se hizo la prueba A/B, en ejecuciones con herramientas MCP, donde suelen explotar los outputs largos y el ruido operacional.
Es el caso de uso más común cuando un agente empieza a ser realmente productivo: tocar repo, ejecutar comandos, interpretar resultados y volver a iterar.
Cursor asegura una reducción del 46,9% de tokens en esa comparativa interna. No suena a una microoptimización, sino a que el agente ha dejado de recitar logs como si formasen parte del razonamiento.

Eso sí, la letra pequeña importa. Es una prueba interna, no un benchmark público con metodología detallada. Aun así, el dato es potente porque ataca el problema donde más duele: sesiones largas, uso intensivo de herramientas y outputs pesados.
A esto se le suma la compatibilidad con estándares como Agent Skills. La idea es sencilla y poderosa: el agente puede incorporar dinámicamente capacidades y scripts de un dominio concreto, en lugar de cargar todo el arsenal desde el principio.
También te puede interesar:ChatGPT ahora se integra con editores de código en macOS con Work WithSi trabajas en un proyecto con tooling específico —migraciones, linters raros, scripts internos—, el agente engancha esas habilidades just in time. Menos contexto fijo, más contexto situacional.
También es una declaración de intenciones. Cursor no está apostando por un “autocomplete caro”, sino por un sistema que coordina herramientas, memoria y procedimientos.
La empresa afirma estar centrando esfuerzos en modelos agentic orientados al desarrollo de software. El mercado se mueve justo ahí: menos demo de prompt, más ejecución real sobre repos, CI, terminal y tooling.

El equipo también ha optimizado su agent harness para los modelos frontier más recientes. Si el enganche entre agente y modelo es malo, da igual lo bueno que sea el LLM: sube la latencia, se desperdicia contexto y se usan mal las herramientas.
Lo diferencial aquí es el enfoque. En vez de pelear por meter más cosas en la ventana de contexto, Cursor asume que la ventana es limitada y diseña alrededor de esa restricción.
El dynamic context discovery estará disponible globalmente para todos los usuarios de Cursor en las próximas semanas, con foco en desarrolladores y equipos que ya trabajan con agentes de programación.
Si funciona como promete, veremos sesiones más largas, más estables y menos alucinaciones provocadas por saturación de contexto. La competencia no se va a quedar quieta: esta gestión de contexto basada en ficheros y recuperación bajo demanda huele a nuevo estándar para agentes serios.
Al final, el futuro del coding con IA no va de tener el modelo más listo en abstracto, sino de construir el sistema que mejor decide qué información entra, cuándo y para qué. Veremos si este enfoque es el punto de inflexión o solo el primer paso hacia agentes que, por fin, trabajan como trabajarías tú: mirando el log correcto en el momento correcto.
Me dedico al SEO y la monetización con proyectos propios desde 2019. Un friki de las nuevas tecnologías desde que tengo uso de razón.
Estoy loco por la Inteligencia Artificial y la automatización.

La Newsletter Diaria Sobre Inteligencia Artificial. Además: Portal de Noticias, Tutoriales, Tips y Trucos de ChatGpt, Openai e Inteligencia Artificial.
Nuestra web está alojada en:


