Google acaba de meter una marcha más a su IA visual con Agentic Vision en Gemini 3 Flash, y lo ha hecho con una promesa bastante concreta: mejoras del 5% al 10% en benchmarks de visión. No se trata simplemente de entender una imagen y describirla mejor, sino de dar un paso más ambicioso: un modelo capaz de actuar sobre la imagen para verificar lo que cree estar viendo, reduciendo errores y aumentando la fiabilidad.
Este lanzamiento está claramente orientado a desarrolladores, empresas e investigadores que viven de exprimir el análisis de imágenes y el razonamiento visual con altos niveles de precisión. Y ahí está el matiz importante: lo interesante no es tanto el titular, sino el “cómo”. Google está empujando a Gemini hacia un perfil más agentic, más de herramienta operativa que de modelo que repite patrones.
Agentic Vision introduce un enfoque iterativo en el análisis visual. El modelo ya no se queda con una única pasada sobre la imagen, sino que refina su interpretación paso a paso, ajustando hipótesis a medida que obtiene nueva información.
Google describe este proceso como un bucle “Think, Act, Observe”. Primero el modelo razona qué necesita para responder correctamente, luego ejecuta acciones concretas, observa el resultado de esas acciones y, con esa nueva evidencia, vuelve a ajustar su análisis. No es solo percepción, es razonamiento activo.
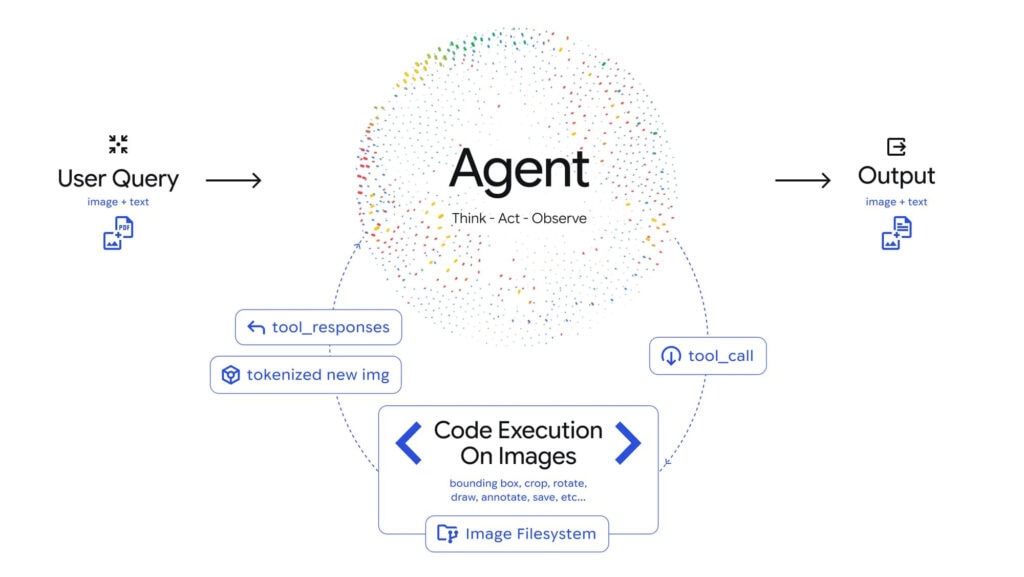
A esto se suma un elemento clave: ejecución de código integrada. Gemini 3 Flash puede manipular imágenes usando Python para resolver partes del problema que antes dependían exclusivamente del “ojímetro” del modelo. La lectura práctica es inmediata: cuando se le pide detectar un detalle minúsculo o extraer una estructura compleja, ya no depende solo de su interpretación interna, sino de operaciones reproducibles y verificables.
Una de las funciones estrella es el zoom automático inteligente, diseñado para capturar detalles finos que suelen pasar desapercibidos. Si la información clave está en una esquina, en una etiqueta diminuta o en una línea apenas visible, el sistema puede acercarse de forma selectiva para no perderla.

Y esto no es menor. En muchos modelos de visión, el fallo no está en entender el contexto general de la imagen, sino en ese pequeño detalle que convierte una respuesta correcta en un error grave.
A ello se suma la anotación de imágenes, que no solo sirve para explicar resultados, sino también para verificarlos. En flujos de trabajo reales, anotar significa dejar evidencia visual de por qué el modelo afirma algo, señalando exactamente dónde lo ha detectado. Esto cambia radicalmente la confianza en sistemas automatizados.
Otra mejora claramente orientada al entorno empresarial es el parsing de tablas complejas dentro de imágenes. No se trata de leer una tabla simple, sino de enfrentarse a celdas fusionadas, estructuras irregulares, documentos escaneados o capturas de pantalla con ruido. Este avance abre la puerta a automatizar procesos que hoy siguen siendo manuales, como auditorías, formularios, informes técnicos o documentación heredada.
Hay una frase que resume el núcleo real del anuncio: entornos de Python deterministas para visualización y análisis. No es solo que el modelo pueda usar Python, sino que puede hacerlo de forma controlada, garantizando resultados consistentes.
Para una empresa que quiere integrar esto en un pipeline de producción, la palabra “determinista” cambia por completo el panorama: menos magia, más ingeniería. Este enfoque reduce la dependencia de respuestas vagas cuando el modelo necesita medir, contar, segmentar o transformar información visual.
En conjunto, esto empuja la IA multimodal hacia un terreno mucho más serio: el de herramientas que calculan, verifican y comprueban, no solo modelos que “parecen inteligentes”.
Google habla de un aumento consistente del 5% al 10% en benchmarks de visión frente a versiones anteriores. No es una mejora puntual ni dependiente del caso, sino un salto estable y repetible en pruebas estándar.
En visión por ordenador, ese margen puede marcar la diferencia entre usar la IA como apoyo o confiarle decisiones reales. Lo más relevante no es solo cuánto mejora, sino qué tipo de tareas mejora: aquellas que exigen precisión, trazabilidad y responsabilidad, donde una alucinación no es anecdótica, sino un problema serio.
Un ejemplo temprano es PlanCheckSolver.com, que ya reporta mejoras medibles en la validación de planos de construcción. Hablamos de escenarios con simbología técnica, escalas, texto diminuto, tablas incrustadas y un contexto que no perdona errores.
Agentic Vision ya está disponible a través de la Gemini API en Google AI Studio y Vertex AI. Google sabe que, si esta tecnología no llega rápido a manos de desarrolladores, se queda en una demo llamativa.
Además, también se está desplegando dentro de la app de Gemini, lo que permite que más usuarios la prueben sin necesidad de montar infraestructura propia. El mensaje estratégico es claro: Google quiere que Gemini no sea solo “otro LLM”, sino una capa de agentes que conecte visión, herramientas y ejecución real.
Google planea ampliar el alcance de este enfoque dando soporte a más tamaños de modelo. No debería quedarse solo en Gemini 3 Flash: veremos versiones más ligeras y otras más potentes, todas con el mismo ADN agentic.
A esto se suma la intención de integrar herramientas adicionales como búsqueda web y búsqueda inversa de imágenes. La combinación es potente: visión que actúa, verificación con fuentes externas y contexto actualizado. Pero también eleva el listón de exigencia: si puede buscar y analizar con código, ya no vale el “me suena que…”.
Este movimiento refuerza la apuesta de Google por una IA multimodal más robusta, operativa y consciente del contexto, pensada para el mundo real y no solo para demos bonitas. Veremos si la competencia responde con algo igual de práctico, porque cuando una IA empieza a interactuar con la imagen en lugar de limitarse a describirla, la conversación cambia por completo.
Me dedico al SEO y la monetización con proyectos propios desde 2019. Un friki de las nuevas tecnologías desde que tengo uso de razón.
Estoy loco por la Inteligencia Artificial y la automatización.

La Newsletter Diaria Sobre Inteligencia Artificial. Además: Portal de Noticias, Tutoriales, Tips y Trucos de ChatGpt, Openai e Inteligencia Artificial.
Nuestra web está alojada en:


