Anthropic acaba de presentar Claude Sonnet 4.6 con una propuesta que suena casi a ciencia ficción aplicada: hasta un millón de tokens de contexto (en beta) para procesar textos extensos, documentación técnica y bases de código sin necesidad de fragmentarlas. En otras palabras, un modelo pensado para tragarse de una sola vez lo que antes obligaba a dividir el trabajo en múltiples partes.
Y, siendo honestos, la mayoría de las personas no “elige un modelo” tras un análisis profundo de arquitectura o benchmarks; simplemente escoge el que le resuelve el problema más rápido ese día, sin detenerse demasiado en lo que ocurre bajo el capó. Sin embargo, cada nuevo lanzamiento reabre la misma pregunta: ¿realmente merece la pena cambiar de herramienta o lo que ya usábamos era suficiente?
En este caso, Sonnet 4.6 se presenta como una mejora transversal: más preciso en codificación, más sólido en razonamiento con contexto largo, más útil para planificación de agentes y más competente en tareas creativas y de trabajo intelectual.
Anthropic lleva tiempo organizando su familia de modelos como si fueran las marchas de un coche: Haiku para ir rápido y barato, Opus para pensar a lo grande y Sonnet como el equilibrio entre potencia y eficiencia. En ese esquema, Sonnet es el modelo “de diario”, donde el coste operativo importa tanto como la calidad del resultado.
La frase verdaderamente interesante del anuncio, sin embargo, es otra: Anthropic asegura que Sonnet 4.6 se acerca en trabajos reales a lo que antes asociábamos con Opus. Si esto se cumple, el impacto no sería una mejora incremental, sino algo más estratégico: pagar menos por tareas que antes exigían subir de categoría.
Uno de los titulares más llamativos es su ventana de contexto de hasta 1.000.000 de tokens en beta. Esto significa que puedes introducir una base de código completa, un contrato kilométrico o una colección amplia de documentos sin dividirlos en diez prompts distintos ni construir un Frankenstein de resúmenes intermedios.

El “troceo”, de hecho, es uno de los impuestos ocultos de usar LLMs de forma profesional: se pierden matices, aparecen inconsistencias y terminas haciendo de gestor manual de memoria. Con un contexto masivo, el flujo se simplifica, aunque aquí entra un matiz importante: no basta con que la ventana sea grande, el modelo debe tener disciplina para mantener coherencia, no alucinar y no desviarse del hilo.
Por supuesto, que exista esa capacidad no implica que siempre sea gratuita en términos de latencia ni que todas las aplicaciones necesiten semejante volumen. Pero abre la puerta a otra manera de trabajar, menos fragmentada y más integrada.
La apuesta más diferencial de Anthropic no es únicamente el millón de tokens, sino el llamado computer use. La idea es que el modelo pueda interactuar con el software como lo haría una persona: abrir aplicaciones, navegar por menús, copiar y pegar, rellenar formularios y encadenar pasos, sin depender exclusivamente de APIs diseñadas a medida.
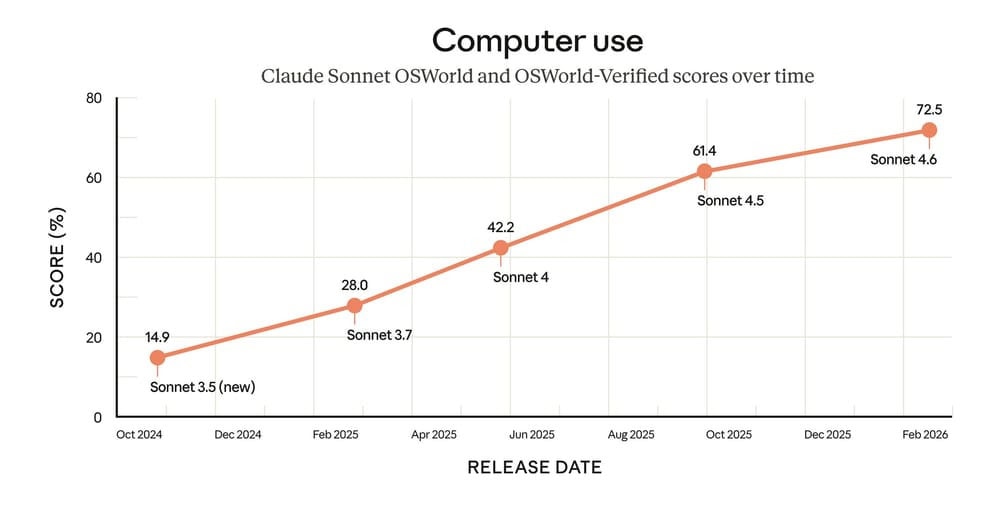
Esto implica pasar de una automatización de laboratorio a un enfoque más pragmático: “haz esta tarea dentro del entorno real que ya tengo configurado”. Según la propia compañía, ha habido mejoras sostenidas en OSWorld-Verified, un banco de pruebas con aplicaciones reales donde la familia Sonnet habría incrementado su rendimiento durante meses.
Ahora bien, aquí aparece la inevitable letra pequeña. Anthropic reconoce límites y riesgos, incluyendo posibles ataques de tipo prompt injection. Cuantas más “manos” tenga el modelo sobre el ordenador, más relevante se vuelve pensar en permisos, aislamiento, confirmaciones explícitas y trazabilidad de acciones. No es solo una cuestión de potencia, sino de gobernanza y control.
La carrera actual de modelos está en un punto curioso: todos buscan un ganador absoluto, pero ese campeón indiscutible no existe. En la comparativa que muestra Anthropic frente a GPT-5.2, el panorama se parece más a un reparto de fortalezas que a un KO técnico.
Según los datos compartidos, Sonnet 4.6 destaca especialmente en OSWorld-Verified, centrado en uso autónomo del ordenador, y muestra ventaja en tareas de oficina medidas como GDPval-AA Elo. También aparece por delante en escenarios de análisis y resolución de problemas como Finance Agent v1.1 y ARC-AGI-2.
Por su parte, GPT-5.2 conserva fortalezas claras en GPQA Diamond (razonamiento de nivel graduado), MMMU-Pro (comprensión visual) y Terminal-Bench 2.0 (programación en terminal). Incluso dentro de la propia tabla aparecen matices como resultados marcados como “Pro”, recordándonos que comparar modelos no es tan limpio como una simple captura de pantalla sugiere.
La conclusión es evidente: depende de si tu día a día consiste en ejecutar tareas aplicadas dentro de flujos reales o en maximizar rendimiento en exámenes académicos y pruebas formales.
En la comparación con Gemini 3 Pro, el duelo se define por la concepción misma de “inteligencia”. Según el enfoque del anuncio, las ventajas de Sonnet 4.6 se concentran en razonamiento aplicado y uso con herramientas, es decir, en productividad y ejecución.
Gemini 3 Pro, en cambio, aparece fuerte en lo que podríamos llamar examen general: mejores resultados en GPQA Diamond, en MMMLU (multilingüe) y en MMMU-Pro cuando se trata de razonamiento visual sin herramientas externas.

Este patrón encaja con algo que ya estamos observando en el mercado: algunos modelos brillan en conocimiento académico y comprensión amplia, mientras otros destacan en ejecución práctica y productividad. Además, la tabla publicada no siempre incluye todos los datos comparables, así que conviene evitar convertir estas diferencias en una guerra simplista de métricas.
Un punto clave es la disponibilidad. Claude Sonnet 4.6 está accesible en todos los planes de Claude, incluido el gratuito, donde pasa a ser la opción por defecto en claude.ai y Claude Cowork. El mensaje implícito es claro: “esto es lo que queremos que uses”.
También está disponible en Claude Code, vía API y en las principales plataformas cloud, manteniendo el mismo precio que Sonnet 4.5. En otras palabras, Anthropic no está diciendo “más caro por ser nuevo”, sino “mejor por el mismo dinero”, una estrategia clásica para ganar cuota en un mercado extremadamente competitivo.
Al final, la decisión vuelve al punto de partida: no necesitas el mejor modelo del planeta, sino el que mejor encaje en tu flujo de trabajo. Si tu prioridad es productividad, workflows largos y que la IA interactúe con el ordenador, Sonnet 4.6 parece una propuesta muy sólida. Si, en cambio, valoras más el razonamiento académico, la comprensión visual o el conocimiento general, GPT-5.2 y Gemini 3 Pro mantienen ventajas claras en varias pruebas.
Quizá la noticia más relevante no sea que un modelo supere a otro en un benchmark concreto, sino que la inteligencia artificial ya no apunta hacia un único campeón universal. Más bien se dirige hacia una fragmentación estratégica, donde eliges herramienta como eliges navegador o editor de código: según tu contexto, tus prioridades y tu forma de trabajar.
Introducir un millón de tokens y potenciar el computer use no es una mejora menor; es una declaración de hacia dónde quieren llevar el trabajo asistido por IA. Ahora queda por ver cómo responderá la competencia, porque lo que está en juego no es solo quién gana en una tabla comparativa, sino qué modelo define la manera en que trabajaremos mañana.
Me dedico al SEO y la monetización con proyectos propios desde 2019. Un friki de las nuevas tecnologías desde que tengo uso de razón.
Estoy loco por la Inteligencia Artificial y la automatización.

La Newsletter Diaria Sobre Inteligencia Artificial. Además: Portal de Noticias, Tutoriales, Tips y Trucos de ChatGpt, Openai e Inteligencia Artificial.
Nuestra web está alojada en: