Perplexity acaba de soltar una pieza que, si te interesa mínimamente la inteligencia artificial, conviene seguir de cerca: DRACO, un benchmark abierto diseñado para medir agentes de investigación compleja. El anuncio llega en un momento en el que el ecosistema de la IA vive en una especie de “cada uno se evalúa como quiere”, con demos llamativas y métricas que muchas veces no se parecen en nada a lo que realmente pedimos cuando necesitamos respuestas fiables.
DRACO significa Deep Research Accuracy, Completeness, and Objectivity, y su ambición es bastante clara: convertirse en un estándar de referencia para evaluar investigación profunda hecha por IA. Aquí la clave no está en ponerle un nombre épico a un test, sino en que el test represente el mundo real y no una especie de olimpíada académica con preguntas de juguete que nadie se hace fuera del laboratorio.
DRACO está diseñado para reflejar escenarios de investigación auténticos, basados en tareas extraídas de millones de consultas reales enviadas a Perplexity Deep Research en producción. Esto apunta directamente a uno de los problemas clásicos de los benchmarks: suelen medir lo que es fácil de medir, no lo que realmente importa cuando te juegas una decisión.
Aquí no se trata solo de “acierta la capital” o “resume este paper”, sino de comprobar si un agente es capaz de investigar con contexto, con matices y con fuentes que soporten un mínimo escrutinio. A esto se suma que DRACO cubre diez dominios distintos, incluyendo áreas tan sensibles como Derecho, Medicina, Finanzas e investigación académica.
Cualquiera que haya intentado sacar algo útil de un LLM en temas legales o médicos sabe que el reto no es únicamente “entender la pregunta”. El verdadero desafío está en no inventarse nada, citar correctamente y explicar de forma verificable, sin obligar al usuario a convertirse en experto para confirmar si la respuesta es fiable.
También te puede interesar:Perplexity Lanza su Nueva Herramienta de Investigación Profunda GratisDRACO no se conforma con una nota global del tipo “78 sobre 100”. En su lugar, evalúa a los agentes en cuatro dimensiones clave: precisión factual, amplitud y profundidad analítica, calidad de la presentación y citación de fuentes. El objetivo es claro: separar al modelo que habla bonito del que investiga de verdad.
Si has probado herramientas de investigación con IA, ya conoces el problema: una respuesta puede ser impecable en tono y estructura, y aun así estar mal desde el primer párrafo. Aquí es donde entran las rúbricas. DRACO incluye rúbricas de evaluación detalladas, refinadas mediante revisión de expertos, que permiten ir más allá del simple “me gusta / no me gusta”.
No es una evaluación subjetiva al aire, sino un sistema con criterios explícitos para identificar qué está bien, qué está incompleto y qué es directamente incorrecto.
DRACO utiliza un enfoque de LLM-as-judge para evaluar las respuestas, pero con un protocolo específico. El proceso contrasta las respuestas con datos reales para reducir la subjetividad al mínimo posible, evitando que sea simplemente “otro modelo opinando” en el vacío.

Esto, por supuesto, no elimina todos los sesgos. Un juez basado en un LLM puede equivocarse, pero el punto importante es otro: DRACO intenta formalizar y estandarizar cómo se juzga una investigación automática, algo que hasta ahora solía quedar peligrosamente difuso.
Perplexity insiste en un matiz que resulta especialmente relevante: DRACO prioriza necesidades reales de usuarios, no tareas sintéticas o puramente académicas. Es una crítica directa a muchos benchmarks que acaban optimizando modelos para ganar rankings, no para resolver problemas reales.
También te puede interesar:Perplexity Anuncia Comet: Su Navegador Web con IAEn el fondo, es el clásico contraste entre “sacar un 10 en el examen” y saber hacer el trabajo cuando importa. A esto se suma otro detalle clave: DRACO es agnóstico al modelo. No está diseñado únicamente para que Perplexity salga bien parada —al menos en teoría—, sino que permite evaluar cualquier sistema de IA con capacidades de investigación, desde agentes basados en modelos comerciales hasta pipelines propios.
Y esto llega en un momento especialmente oportuno, porque estamos en plena fiebre de los agents: todos prometen investigar, planificar, ejecutar y citar… hasta que les pides algo fino y el sistema se desmorona.
Según los primeros resultados publicados, Perplexity Deep Research lidera en precisión y velocidad, destacando especialmente en dominios exigentes como consultas legales y personalizadas. Evidentemente, esto también funciona como escaparate del producto: si tú publicas el examen y sales primero, el mensaje es bastante claro.
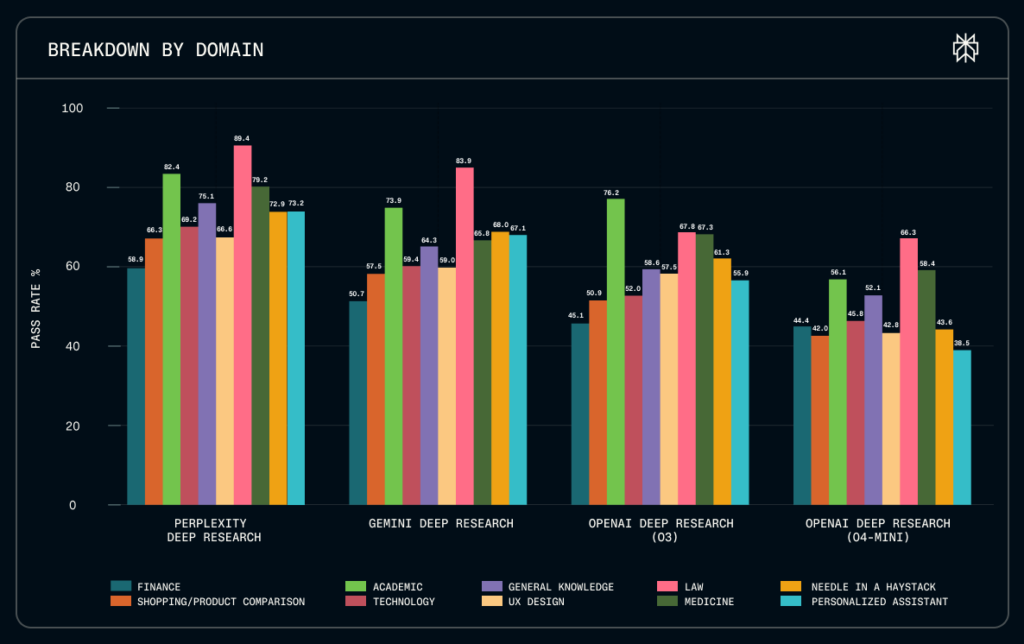
Sin embargo, lo realmente relevante no es tanto quién encabeza la tabla, sino que DRACO se libere y se ponga a disposición pública. Cuando un benchmark es accesible para desarrolladores, investigadores y organizaciones, la conversación cambia por completo: ya no basta con decir “mi agente es buenísimo”, sino que toca demostrarlo con puntuaciones en un estándar replicable.
Si DRACO logra adopción, veremos presión real justo donde más duele: mejor citación de fuentes, mayor precisión factual y menos confusión entre fluidez y verdad. En otras palabras, menos magia de demo y más ingeniería seria de investigación asistida.
Ahora viene la parte difícil: que la industria lo use, lo critique, lo itere y lo convierta en una referencia de facto. Si DRACO consigue eso, no solo cambiará cómo se comparan los agentes de IA, sino qué entendemos por “investigación” cuando quien la realiza es una máquina. Y todo apunta a que este es apenas el comienzo de una etapa en la que los agentes dejarán de competir por hablar mejor y empezarán a demostrar mejor.
Me dedico al SEO y la monetización con proyectos propios desde 2019. Un friki de las nuevas tecnologías desde que tengo uso de razón.
Estoy loco por la Inteligencia Artificial y la automatización.

La Newsletter Diaria Sobre Inteligencia Artificial. Además: Portal de Noticias, Tutoriales, Tips y Trucos de ChatGpt, Openai e Inteligencia Artificial.
Nuestra web está alojada en:


