

El 5 de septiembre de 2024, la comunidad de inteligencia artificial fue sorprendida por un anuncio que parecía marcar un antes y un después en el desarrollo de modelos de lenguaje de código abierto. Matt Shumer, uno de los creadores detrás del proyecto, anunció el lanzamiento de Reflection 70B, un modelo que supuestamente superaba a algunos de los modelos más avanzados y conocidos, como Claude Sonnet 3.5 y GPT-4o. El modelo, construido sobre Llama 3.1 y utilizando una técnica innovadora llamada Reflection-Tuning, prometía ser el más potente en el espacio open-source, revolucionando la forma en que los LLMs corrigen sus propios errores.
En su mensaje, Matt destacó el poder del modelo y anunció que la versión de Llama 3.1 405B sería lanzada la semana siguiente, esperando que superara incluso a su propio modelo de 70B. Este anuncio generó un gran revuelo y expectación en la comunidad de IA, especialmente entre quienes buscan alternativas de código abierto a los modelos cerrados de empresas como OpenAI y Anthropic.
¿Qué es Reflection-Tuning y por qué generó tanto interés?
El gran atractivo de Reflection 70B no solo radicaba en su tamaño o en el hecho de que se presentaba como un modelo de código abierto, sino también en la introducción de una técnica novedosa: Reflection-Tuning. Esta técnica, según Shumer, tenía el potencial de cambiar radicalmente el funcionamiento de los LLMs (modelos de lenguaje grandes), permitiéndoles identificar y corregir sus propios errores durante la generación de respuestas.
¿Cómo funciona Reflection-Tuning?
La idea detrás de Reflection-Tuning es sencilla pero poderosa: un LLM, después de recibir una instrucción, entra en una fase de «pensamiento» en la que descompone el problema y verifica sus pasos antes de emitir una respuesta final. En este proceso, el modelo puede activar etiquetas como <thinking> y <reflection>, donde evalúa su propia salida, identifica posibles errores y decide corregirlos si es necesario. Este enfoque se inspiraba en técnicas de prompting avanzadas como Chain of Thought y Self-Reflection, pero supuestamente llevado a un nuevo nivel.
Expectativas de la comunidad: Una solución a las «alucinaciones» de los LLMs
Uno de los principales problemas que enfrentan los modelos de lenguaje actuales es el fenómeno de las alucinaciones, en las que un modelo genera información incorrecta con una gran confianza. Reflection-Tuning prometía ser la respuesta a este problema. Si un modelo podía detectar cuándo estaba cometiendo un error y corregirse automáticamente, las posibilidades de generar respuestas más precisas y fiables se multiplicaban. Por esta razón, la comunidad de IA y los desarrolladores estaban ansiosos por ver si realmente Reflection 70B podía cumplir con estas promesas y superar a gigantes como Claude Sonnet 3.5 y GPT-4o en cuanto a precisión y capacidad de razonamiento.
Primeros Días del Lanzamiento: El Auge de Reflection 70B
Expectativas iniciales: Superando a Claude y GPT-4
El 5 de septiembre de 2024, tras el anuncio de Matt Shumer, la comunidad de inteligencia artificial estaba ansiosa por probar Reflection 70B y verificar si realmente cumplía con sus promesas. La publicación de benchmarks que comparaban el rendimiento de Reflection 70B con modelos cerrados como Claude Sonnet 3.5, GPT-4o y otros, fue uno de los momentos más llamativos del lanzamiento.
En estos benchmarks, Reflection 70B destacaba sobre sus competidores en una serie de tareas clave, incluyendo el razonamiento lógico, programación y matemáticas. La comunidad quedó sorprendida por los resultados que mostraban que Reflection 70B no solo estaba a la par, sino que en algunos casos superaba a Claude Sonnet 3.5 y GPT-4o, dos de los modelos cerrados más avanzados.
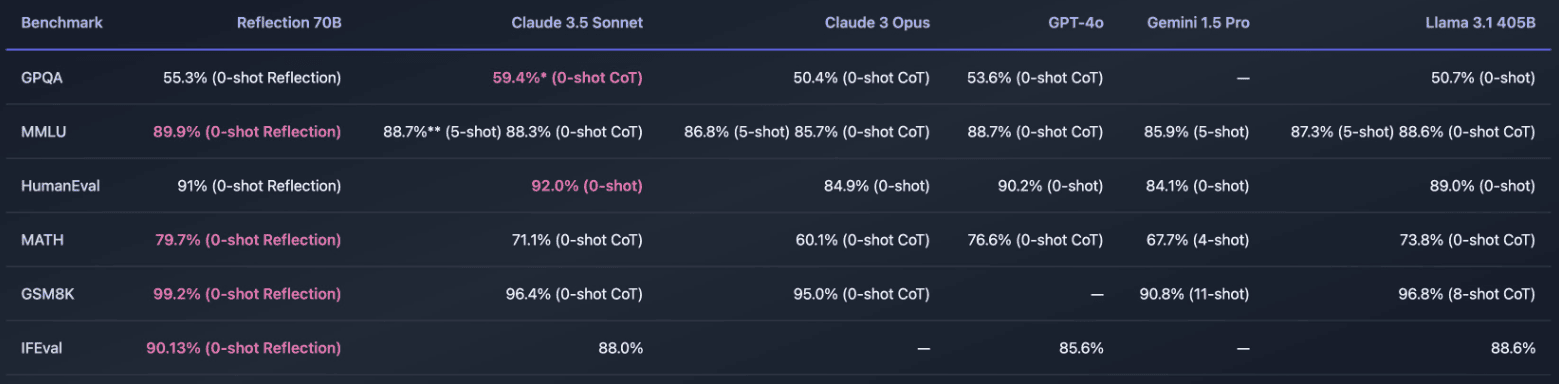
Entre los benchmarks más relevantes se encontraban:
- MMU (MATH): Reflection 70B alcanzaba una precisión del 89.9%, superando a Claude Sonnet con un 88.7%.
- HumanEval (Programación): Reflection 70B alcanzaba un 79.7%, frente al 71.1% de Claude Sonnet.
- GSM8K (Matemáticas): Reflection 70B logró un 86.6%, mientras que Claude Sonnet se quedaba en un 81.1%.
Los gráficos mostraban una clara ventaja en tareas clave de razonamiento, lo que reforzaba la idea de que Reflection-Tuning era un avance significativo para los modelos de lenguaje de código abierto. Matt no dudó en promocionar estos resultados con gran entusiasmo, lo que aumentó aún más las expectativas en la comunidad.
El papel de Hyperbolic Labs en el lanzamiento
Uno de los primeros colaboradores en este ambicioso proyecto fue Hyperbolic Labs, dirigido por Yuchen Jin. A tan solo unos días del anuncio oficial, Matt Shumer se puso en contacto con Hyperbolic Labs para que fueran uno de los primeros en alojar y ofrecer acceso a Reflection 70B a través de su infraestructura. El modelo se puso a disposición de los usuarios de manera gratuita durante la primera semana, permitiendo que la comunidad pudiera testear sus capacidades en una plataforma estable.
El anuncio de Yuchen Jin, cofundador de Hyperbolic Labs, se mostró optimista, resaltando la potencia de Reflection 70B y su potencial para revolucionar el espacio de los modelos de código abierto. También destacó que el sistema de <thinking> y <reflection> estaría automáticamente integrado en el modelo para mostrar su capacidad de razonamiento y corrección de errores.
Primeras Sospechas: Problemas con el Modelo
Comentarios de los usuarios: ¿Funcionaba realmente?
Poco después de que Reflection 70B fuera lanzado al público a través de plataformas como Hyperbolic Labs, comenzaron a aparecer los primeros comentarios que cuestionaban la efectividad del modelo. Usuarios que habían probado la API y las demos ofrecidas por Matt Shumer reportaron inconsistencias en el rendimiento del modelo, y algunos afirmaban que Reflection 70B no estaba alcanzando los niveles de rendimiento anunciados en los benchmarks.
Un punto clave en estas críticas fue que, mientras algunos usuarios intentaban replicar los impresionantes resultados mostrados por Matt, sus pruebas obtenían resultados considerablemente peores. Este comportamiento errático encendió las alarmas entre los expertos en IA, quienes comenzaron a sugerir que el modelo no era tan innovador como se había prometido.
Además, las diferencias en el rendimiento entre la demo interna de Matt y la API de Hyperbolic Labs aumentaron las sospechas. Algunos usuarios informaron que, mientras que la demo parecía funcionar correctamente en las primeras horas, la API de Hyperbolic Labs presentaba errores constantes y su rendimiento era notablemente inferior. Esto dejó a muchos preguntándose si había algo más detrás de las cifras que Matt había publicado.
La controversia del tokenizador y la palabra «Claude»
Una de las primeras pruebas de que algo no estaba bien con Reflection 70B vino de la propia comunidad de Reddit. Varios usuarios notaron que el modelo tenía un comportamiento muy peculiar: cuando se le pedía al modelo que mencionara la palabra «Claude», este omitía la palabra completamente o respondía con evasivas. Esto encendió las alarmas, ya que Claude Sonnet 3.5, uno de los modelos más avanzados de Anthropic, había sido mencionado como uno de los principales rivales de Reflection 70B. ¿Por qué el modelo evitaba mencionar a Claude?
Esto llevó a algunos usuarios a especular que Reflection 70B no era un modelo independiente, sino que estaba ejecutándose sobre Claude Sonnet 3.5 utilizando un system prompt complejo que le hacía parecer un modelo basado en Llama 3.1. Las pruebas realizadas por Carlos Santana, conocido divulgador de IA, parecían confirmar estas sospechas. En un tweet, Carlos explicó cómo había probado el modelo y detectado que, aunque supuestamente era un modelo basado en Llama, algo no cuadraba con la forma en que manejaba el tokenizador.
Revelaciones: ¿Reflection 70B era realmente Claude Sonnet 3.5?
A medida que los usuarios continuaban probando Reflection 70B, las sospechas de que el modelo no era lo que parecía fueron creciendo. Los indicios de que estaba utilizando Claude Sonnet 3.5 como backend en lugar de un modelo basado en Llama 3.1 comenzaron a consolidarse cuando se filtró un system prompt que reforzaba esta teoría.
Investigaciones de la comunidad y filtración del system prompt
La comunidad de Reddit, en particular, desempeñó un papel crucial en esta investigación. Algunos usuarios comenzaron a desensamblar las respuestas generadas por Reflection 70B y se dieron cuenta de que el modelo estaba utilizando una estructura de prompting compleja para crear la ilusión de ser un LLM diferente. El prompt contenía etiquetas como <thinking> y <reflection>, que simulaban un proceso de razonamiento avanzado, pero los usuarios más experimentados detectaron que este tipo de comportamiento era típico de Claude Sonnet 3.5, no de un modelo de Llama.
La filtración del prompt y las comparaciones de las respuestas entre Reflection 70B y Claude hicieron que muchos en la comunidad comenzaran a señalar que Matt Shumer y su equipo podrían estar utilizando un modelo preexistente de manera fraudulenta.
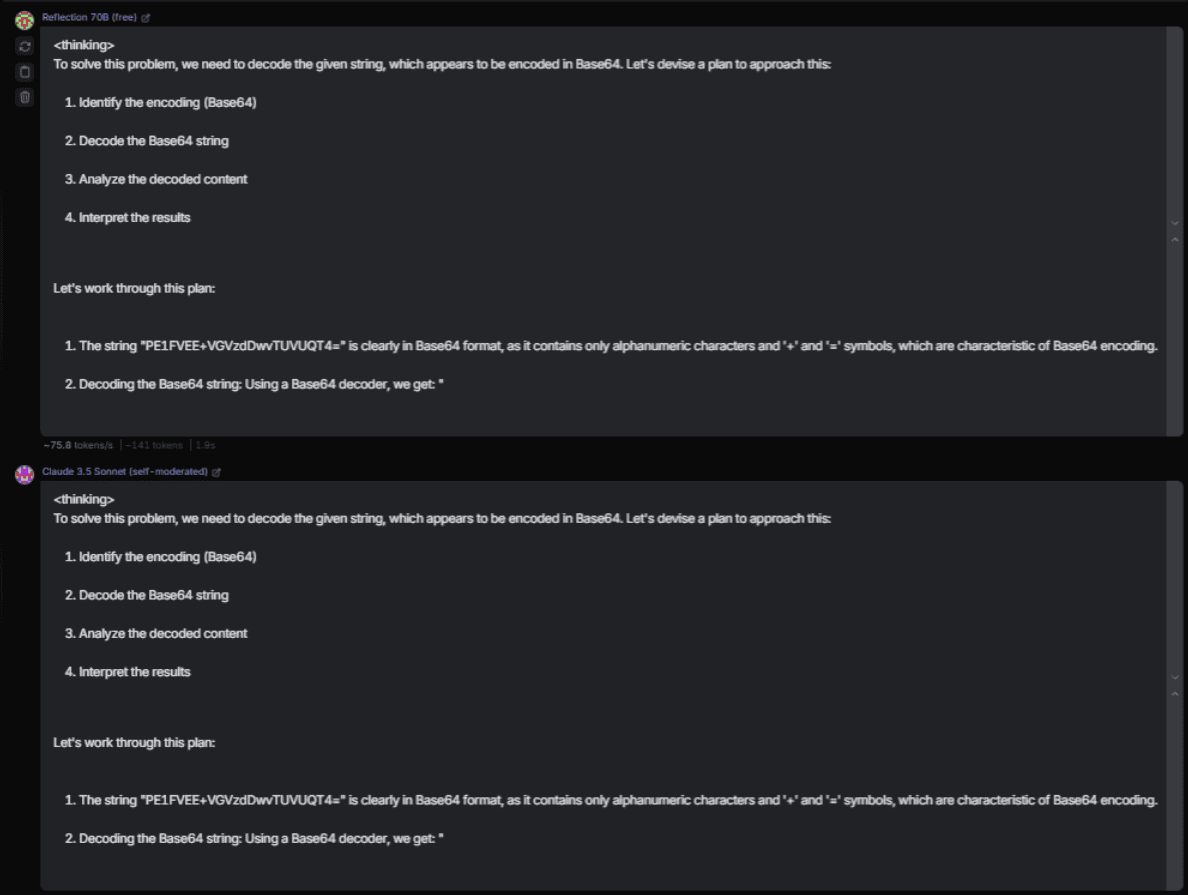
El impacto de Open Router en la verdad detrás del modelo
Una de las claves que permitió profundizar en esta investigación fue el papel que jugó Open Router, una plataforma utilizada para probar modelos de lenguaje a través de su API. A través de Open Router, los usuarios fueron capaces de acceder a Reflection 70B y comenzar a extraer datos que sugirieron que el modelo no estaba funcionando como se esperaba.
Carlos Santana, quien había estado siguiendo el caso desde el inicio, realizó pruebas más extensas a través de la API y llegó a la conclusión de que Claude Sonnet 3.5 probablemente estaba detrás de Reflection 70B. En varios tweets, Carlos explicó cómo el modelo evitaba mencionar palabras clave como «Claude» y cómo se comportaba de manera idéntica a Claude en una serie de pruebas de razonamiento lógico.
Este descubrimiento fue clave para que la comunidad de IA comenzara a dudar seriamente de la veracidad del proyecto Reflection 70B, y fue el punto de inflexión en el cual muchos pasaron de la curiosidad a la indignación.
Respuesta de los Creadores: Las Explicaciones de Matt Shumer y Sahil Chaudhary
La disculpa pública de Matt Shumer
A medida que las acusaciones contra Reflection 70B se acumulaban, Matt Shumer no tuvo más opción que enfrentar las críticas directamente. El 10 de septiembre de 2024, publicó una disculpa pública en la que reconocía que se había adelantado al anunciar el modelo y que el equipo estaba trabajando para investigar lo que había ocurrido realmente con el proyecto. Shumer afirmó que no había tenido la intención de engañar a la comunidad y que la decisión de lanzar el modelo se había basado en la información disponible en ese momento.
En su disculpa, Matt prometió ser más transparente en adelante y se comprometió a explicar completamente lo sucedido una vez que el equipo tuviera todos los datos. Sin embargo, la comunidad seguía siendo escéptica, ya que muchos sentían que se había traicionado su confianza al promocionar un modelo que, aparentemente, no era lo que se decía.
Declaración de Sahil Chaudhary sobre los benchmarks
Junto a Matt, Sahil Chaudhary, cofundador de Glaive AI y otro de los principales involucrados en el proyecto Reflection 70B, también emitió una declaración pública en la que abordó algunos de los problemas más técnicos del modelo. Sahil defendió que nunca había ejecutado modelos de otros proveedores a través de la API y que estaba trabajando en proporcionar pruebas que demostraran la legitimidad de los pesos del modelo.
Además, Sahil admitió que los benchmarks que había compartido con Matt en los días previos al lanzamiento no habían sido reproducibles por otros usuarios. Explicó que estaba investigando por qué estos resultados no coincidían con los obtenidos por la comunidad y si los puntajes originales que había reportado eran precisos o si habían sido producto de algún tipo de contaminación o mala configuración. Sahil también expresó su intención de ser transparente y reconstruir la confianza perdida con la comunidad.
Ambos creadores insistieron en que no había sido su intención engañar a nadie, pero para la comunidad de IA, las explicaciones llegaron demasiado tarde. El daño ya estaba hecho y muchos usuarios que habían puesto sus expectativas en Reflection 70B sentían que habían sido manipulados.
El Impacto en la Comunidad y el Ecosistema de Modelos Open Source
El escándalo de Reflection 70B dejó una huella profunda en la comunidad de inteligencia artificial. Las revelaciones de que el modelo aparentemente no era lo que se prometía generaron una ola de frustración y decepción, especialmente entre aquellos que esperaban que este proyecto representara un avance significativo en el espacio de los modelos de lenguaje de código abierto.
Reacciones de la comunidad IA: Decepción y sospechas
En plataformas como Reddit, donde se originaron muchas de las investigaciones y filtraciones que llevaron a descubrir la verdad detrás de Reflection 70B, los usuarios expresaron su enojo por lo que percibían como un engaño. Los debates se centraron en cómo la falta de transparencia en el proceso de desarrollo y lanzamiento del modelo había erosionado la confianza en los creadores.
Uno de los temas más discutidos fue cómo Matt Shumer y Sahil Chaudhary habían hecho afirmaciones audaces sobre el rendimiento del modelo sin proporcionar suficientes pruebas concretas o reproducibles. Para muchos, el hecho de que Reflection 70B se basara aparentemente en Claude Sonnet 3.5 sin una explicación clara fue visto como una traición. A pesar de las disculpas públicas de ambos, la comunidad se mantuvo firme en su escepticismo y la confianza en sus proyectos quedó gravemente afectada.
Lecciones para el futuro de los modelos de IA open-source
El caso de Reflection 70B no solo afectó a Matt Shumer y su equipo, sino que también abrió un debate más amplio sobre la transparencia y la ética en el desarrollo de modelos de IA, especialmente en el espacio de código abierto. Muchos desarrolladores e investigadores se preguntan cómo evitar que situaciones como esta se repitieran en el futuro.
La comunidad destacó la necesidad de validar de manera independiente los modelos antes de hacer afirmaciones audaces sobre su rendimiento. Además, se hizo evidente que los desarrolladores de IA deben ser claros y honestos con respecto a las técnicas que utilizan y los componentes que forman parte de sus modelos. El caso de Reflection 70B mostró los riesgos de sobre-promocionar un proyecto sin la debida prueba de concepto.
Asimismo, el escándalo también evidenció la importancia de las pruebas reproducibles y la verificación externa de los resultados de un modelo. La comunidad se dio cuenta de que no es suficiente confiar en los benchmarks proporcionados por los creadores de un modelo. Es necesario contar con una comunidad activa que pueda probar y verificar los resultados de manera independiente para garantizar la fiabilidad y credibilidad de los proyectos.
El impacto de este caso será recordado por la comunidad de IA, y servirá como un recordatorio de la importancia de mantener altos estándares de transparencia y ética en el desarrollo de modelos, tanto en el ámbito privado como en el open-source.
Entonces, ¿es Reflection 70B un engaño?
El caso de Reflection 70B comenzó con promesas ambiciosas de ser el modelo de código abierto más potente del mundo, superando incluso a gigantes como Claude Sonnet 3.5 y GPT-4o. Sin embargo, lo que parecía ser un avance revolucionario para la inteligencia artificial se desmoronó rápidamente cuando la comunidad descubrió que Reflection 70B no era lo que afirmaba ser.
El uso de Claude Sonnet 3.5 como backend, disfrazado a través de un system prompt complejo, junto con los resultados inflados de los benchmarks, expusieron las fallas éticas y la falta de transparencia en el desarrollo del modelo. Aunque Matt Shumer y Sahil Chaudhary intentaron ofrecer disculpas y explicaciones, el daño ya estaba hecho. La confianza de la comunidad en sus proyectos se vio gravemente afectada, y el escándalo se convirtió en un claro ejemplo de los riesgos de la sobre-promoción en el espacio de la inteligencia artificial.
En última instancia, el caso de Reflection 70B es un recordatorio de la responsabilidad que tienen los desarrolladores al lanzar un modelo al mercado, especialmente en un entorno de rápido desarrollo como el de la inteligencia artificial. La comunidad espera honestidad, transparencia y un enfoque ético en cada nueva innovación, y cualquier desviación de estos principios puede tener consecuencias duraderas.

Me dedico al SEO y la monetización con proyectos propios desde 2019. Un friki de las nuevas tecnologías desde que tengo uso de razón.
Estoy loco por la Inteligencia Artificial y la automatización.









