

¿Cuántas veces le has pedido a una inteligencia artificial algo muy sencillo y te ha devuelto un ensayo interminable? Es una absoluta pérdida de tiempo. Y de dinero, por supuesto. Tras meses de rumores en el sector, Anthropic ha dado un golpe sobre la mesa presentando oficialmente Claude Opus 4.8. La novedad no es que sea más inteligente por arte de magia, sino que ahora incorpora un selector para decidir exactamente cuánta materia gris queremos que gaste en cada interacción.
Y es que hasta ahora, hablar con un LLM de frontera era como encender un reactor nuclear para tostar pan. El nuevo control de esfuerzo de Claude viene para acabar de raíz con este despropósito técnico. Lanzado de forma bastante discreta el pasado mes de diciembre de 2025 dentro de la API del modelo Opus 4.5, este esperado parámetro llega por fin de forma nativa a las interfaces de usuario de claude.ai y Cowork.
En concreto, este ajuste determina de manera quirúrgica la cantidad de tokens que el modelo puede consumir al procesar tu solicitud. No estamos ante un simple limitador de palabras. Su activación afecta drásticamente al tiempo de razonamiento de la IA, a su capacidad para invocar herramientas externas y, si el usuario lo permite, al razonamiento extendido. Así de simple.
Cinco marchas para domar el consumo de tu IA
Como era de esperar, la compañía no ha dejado el rendimiento en manos de un básico interruptor de encendido y apagado. Han estructurado la capacidad de procesamiento de sus redes neuronales en cinco niveles de esfuerzo totalmente distintos. Mientras que modelos muy solventes como Claude Sonnet 4.6 ofrecen cuatro posiciones, la bestia de Claude Opus 4.8 despliega el arsenal completo, permitiendo un ajuste milimétrico de los recursos.
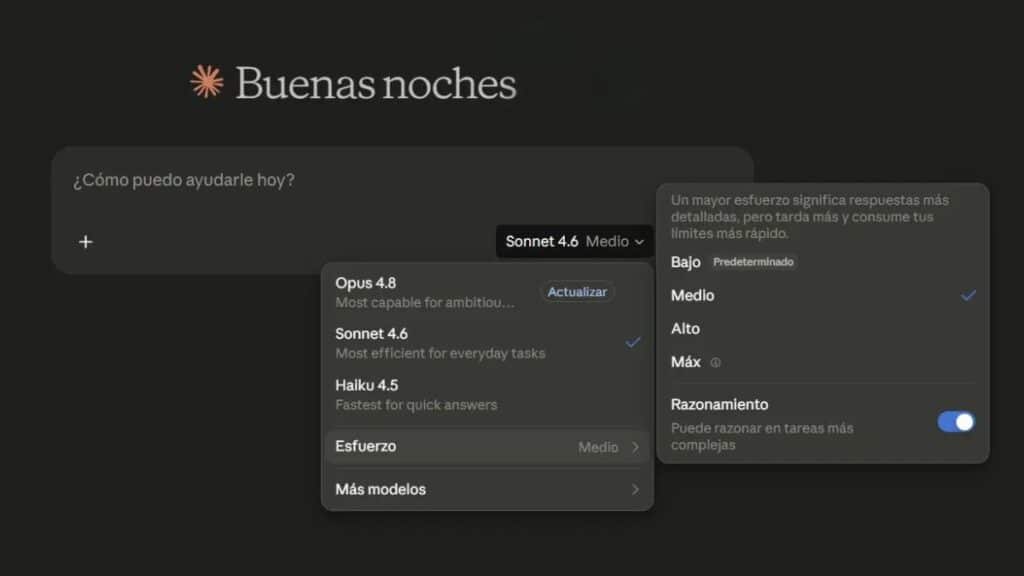
Si miramos los números y la documentación oficial, cada nivel está pensado para un flujo de trabajo muy particular dentro de tu día a día corporativo:
- Nivel Bajo: Es el modo de máximo ahorro. Prioriza la eficiencia brutal, omite el razonamiento oculto en tareas fáciles y acorta muchísimo las respuestas. Un detalle genial es que en este modo, si la tarea es ambigua, el modelo se frena y te pide aclaraciones en lugar de avanzar por su cuenta y alucinar.
- Nivel Medio: El rey indiscutible del equilibrio. Aplica la lógica pesada solo cuando el código o el prompt lo exigen de verdad. Es el hábitat natural para la programación general y las tareas autónomas del día a día.
- Nivel Alto: Viene configurado por defecto al abrir un chat. Si vas a lanzarle un bloque masivo de datos para un análisis detallado o tienes una sesión infernal de depuración, no lo bajes de aquí. Necesitas toda la calidad posible.
- Nivel Extra: Disponible exclusivamente en la gama alta como Opus 4.7 y 4.8. Aquí la IA se vuelve implacable y muy terca. Explora muchísimas más vías lógicas, abusa de las llamadas a herramientas y no pierde el hilo en sesiones largas. Anthropic lo recomienda encarecidamente para arrancar agentes autónomos.
- Nivel Max: La barra libre de computación. Se eliminan de un plumazo las restricciones de tokens y el modelo entrega todo lo que tiene dentro. Sistemas como el Mythos Preview o Sonnet 4.6 también soportan este límite extremo.
Pero claro, pisar el acelerador a fondo no siempre es una gran idea si miras la factura de la nube a final de mes. La propia Anthropic avisa de que el salto cualitativo del nivel Max frente a las configuraciones inferiores suele ser bastante marginal en el uso cotidiano. Pagar ese duro peaje de inferencia es una locura a menos que te enfrentes a decisiones críticas de arquitectura de software o a revisiones de seguridad donde un error sale muy caro.
El mito de los tokens: gastar más no te hace más listo
A ello se le suma una cuestión de diseño de interfaz que aporta una agilidad tremenda. El nivel de esfuerzo no es una condena inamovible que debas elegir al arrancar el chat. Puedes modificarlo en cualquier instante de la misma conversación. Solo tienes que ir al selector del modelo, acceder a la pestaña de «Esfuerzo» y subir o bajar la marcha según el problema que tengas entre manos. Una auténtica maravilla de la usabilidad.
Evidentemente, hay una regla no escrita que todo usuario técnico debe grabarse a fuego. Un mayor nivel de esfuerzo no equivale a mayor inteligencia. Es decir, si redactas unas instrucciones deficientes o le proporcionas a la máquina un contexto mediocre, el modelo en nivel Max simplemente será un inútil muy caro que quemará miles de tokens para estrellarse contra el mismo muro.
Básicamente, si notas que tienes que subir este parámetro constantemente para que la IA haga su trabajo, el problema no es del hardware de Anthropic, es de tus prompts. Refinar tu forma de pedir las cosas siempre será mucho más rentable que tirar de fuerza bruta computacional. Con este lanzamiento, la guerra del sector cambia de foco: ya no importa solo quién tiene la inteligencia artificial más potente, sino quién nos da el panel de mandos para controlar su voracidad financiera. El balón está ahora en el tejado de OpenAI.

Me dedico al SEO y la monetización con proyectos propios desde 2019. Un friki de las nuevas tecnologías desde que tengo uso de razón.
Estoy loco por la Inteligencia Artificial y la automatización.






