

Llevamos años acostumbrados a ver cómo la inteligencia artificial «teclea» las respuestas palabra por palabra frente a nuestros ojos en la pantalla. Es un efecto casi hipnótico, pero computacionalmente hablando es una pesadilla de ineficiencia. Ahora, Google ha decidido dinamitar esa norma con su nuevo experimento. Se llama DiffusionGemma y cambia por completo las reglas del juego al escupir bloques enteros de texto de golpe. Adiós a la espera desesperante.
Según han detallado los ingenieros de la compañía en una publicación en su blog, este modelo alcanza picos de velocidad absurdos al abandonar el clásico enfoque secuencial. Es un movimiento arriesgado. Y promete cambiar cómo interactuamos con el hardware local.
De escribir palabra por palabra a generar bloques enteros
La inmensa mayoría de los LLM actuales usan un sistema autorregresivo. Piensan un token, lo imprimen, y usan ese mismo token para calcular el siguiente. Es una cadena de montaje infinita que siempre avanza de izquierda a derecha. Un proceso seguro, pero desesperantemente lineal.
El problema evidente es que tu potente tarjeta gráfica se queda cruzada de brazos. La GPU permanece inactiva valiosas fracciones de segundo esperando la siguiente palabra, desperdiciando recursos locales de forma masiva. Hay cuellos de botella por todas partes.
Aquí es donde el nuevo modelo rompe el molde por completo. En lugar de ir paso a paso, DiffusionGemma genera bloques de 256 tokens simultáneamente. Una auténtica locura técnica.
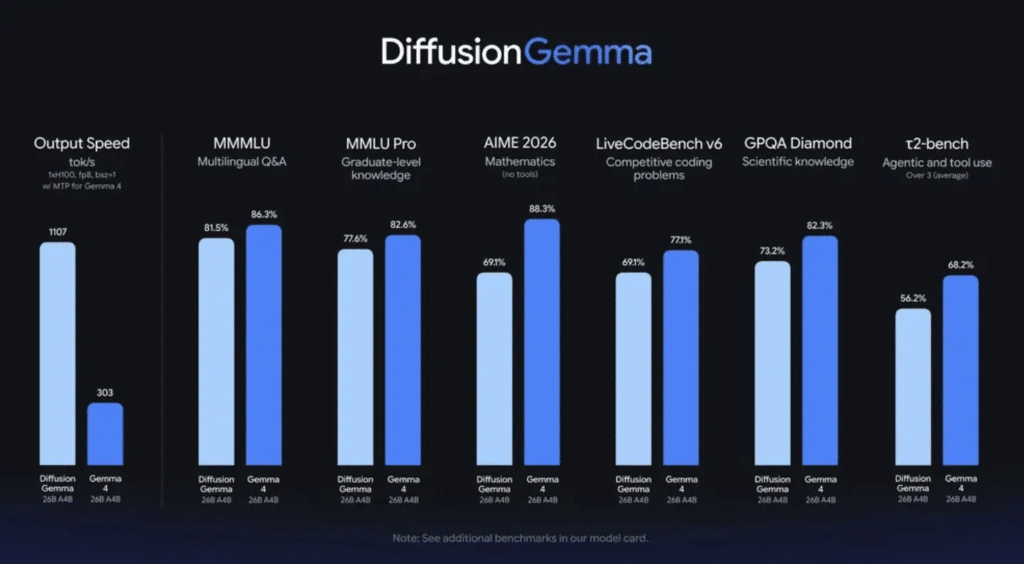
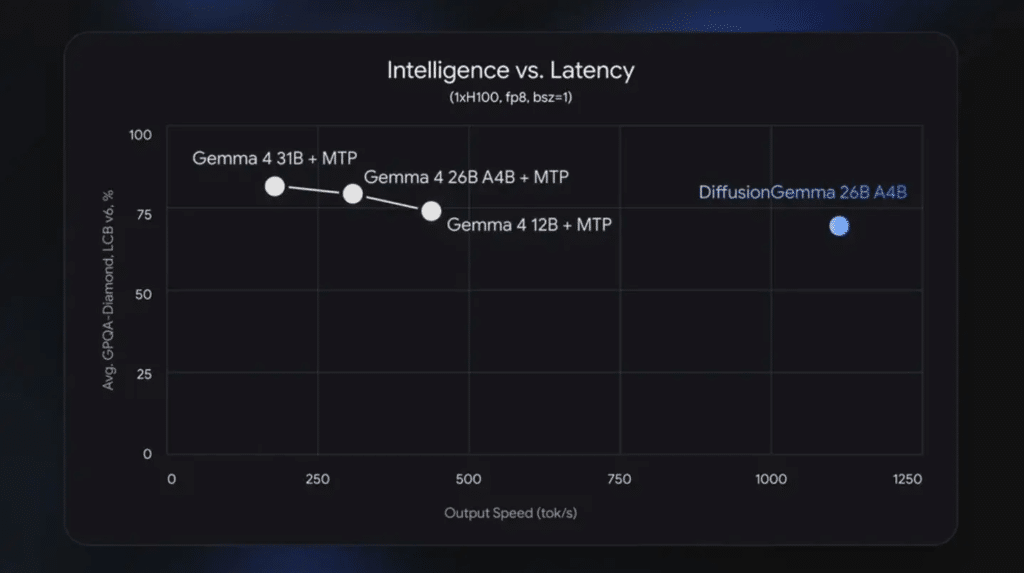
Básicamente, inunda la capacidad matemática del hardware para hacer el trabajo muchísimo más rápido. Y los resultados en las pruebas de estrés hablan por sí solos. En una brutal GPU NVIDIA H100 de grado empresarial, este bicho supera los 1.000 tokens por segundo.

Si echamos cuentas, hablamos de multiplicar por cuatro el rendimiento bruto de los modelos Gemma 4 convencionales, logrando casi diez veces la velocidad de GPT-5.4 mini. Así de simple.
El truco oculto: usar la lógica de la generación de imágenes
Quizás te preguntes cómo demonios es posible adivinar 256 palabras a la vez sin que la frase resultante pierda todo el sentido sintáctico. Parece magia negra de la computación. La respuesta técnica está en el refinamiento iterativo. Si alguna vez has usado herramientas como DALL-E o Midjourney, sabrás que empiezan con una mancha de ruido pixelado y la van puliendo en segundos hasta sacar una imagen fotorrealista impecable.
Pues esta IA hace exactamente lo mismo, pero aplicado a las letras. Arranca con texto completamente aleatorio y le da múltiples pasadas ultrarrápidas hasta que las oraciones cobran sentido. Modela el lenguaje como si fuera una fotografía.
A ello se le suma una arquitectura inteligente de atención bidireccional. Al procesar todo el bloque de golpe, el modelo no está ciego; puede mirar hacia adelante y hacia atrás en la frase para entender el contexto global.
Esto lo convierte en una bestia para tareas complejas como rellenar huecos en código de programación o editar un texto directamente en línea. Al no ser un modelo lineal, no necesita releer desde el principio cada vez que haces un cambio. Responde al instante.
Un gigante optimizado para los ordenadores de casa
Si miramos bajo el capó, no estamos ante un modelo monolítico pesado y torpe. La gente de Google ha optado por una arquitectura Mixture of Experts (MoE), lo que garantiza una eficiencia brutal en equipos domésticos.
En números puros, cuenta con un total de 26.000 millones de parámetros durmiendo en su interior. Sin embargo, su verdadera magia reside en que durante la fase de inferencia solo necesita activar 3.800 millones de esos parámetros. Una fracción diminuta.
Dicho de otro modo, es lo suficientemente ágil como para correr en local. Si tienes un PC potente con una gráfica de 18 GB de VRAM, como una codiciada RTX 4090 o las futuras 5090, puedes ejecutarlo en tu propio escritorio sin pagar suscripciones mensuales a la nube. Ni se inmuta.
Por si fuera poco, han lanzado este avance bajo una filosofía totalmente abierta. Los pesos ya están disponibles en Hugging Face bajo una permisiva licencia Apache 2.0 para su uso libre comercial.
Además, la compañía ya colabora activamente con la comunidad open-source aportando herramientas para vLLM, MLX y Transformers, buscando facilitar la integración y el soporte oficial para el popular ecosistema de llama.cpp en las próximas semanas.
La letra pequeña: sacrificar precisión por pura velocidad
Llegados a este punto, puede parecer que hemos encontrado el asesino definitivo de los modelos tradicionales. El Santo Grial de la IA rápida y barata. Pero la realidad suele ser menos glamurosa. Desde Mountain View admiten sin tapujos que esta ganancia brutal de rendimiento tiene un peaje muy claro en la calidad del texto generado. La velocidad exige sacrificios.
Siendo honestos, los modelos de la familia Gemma 4 estándar siguen produciendo textos más creativos, precisos y fiables para un entorno de producción real o de cara al cliente final. No hay color en ese aspecto.
Entonces, ¿para qué sirve realmente DiffusionGemma? Su ecosistema natural es el prototipado rápido, la edición de texto en tiempo real y la experimentación loca en local. Es un patio de recreo increíble para desarrolladores que necesitan respuestas instantáneas sin importarles si la prosa es un poco plana.
Nos estamos asomando a un cambio de paradigma bestial en cómo interactuamos con las máquinas en nuestras propias casas. Que un modelo experimental pueda escupir un bloque entero de texto localmente abre la puerta a una nueva generación de asistentes ultrarrápidos.
Veremos si el resto de la industria tecnológica decide replicar esta arquitectura o si la vieja confiable del sistema autorregresivo sigue aferrada al trono unos años más. La pelota, ahora mismo, está en el tejado de la competencia.

Me dedico al SEO y la monetización con proyectos propios desde 2019. Un friki de las nuevas tecnologías desde que tengo uso de razón.
Estoy loco por la Inteligencia Artificial y la automatización.






