

Nos acaban de volar la cabeza con el enésimo giro de guion en la guerra de la inteligencia artificial. Si pensabas que los modelos más potentes del mercado iban a seguir siendo un lujo reservado a grandes corporaciones, estabas muy equivocado. Según Reuters, la empresa asiática ha decidido hacer permanente la salvaje rebaja del 75 % en su modelo estrella, el DeepSeek-V4-Pro. Un movimiento tectónico que deja tiritando a los pesos pesados del sector.
Y es que no estamos hablando de una simple promoción por tiempo limitado ni de un modelo ligero recortado para rascar unos céntimos en la API. Han rebajado a la cuarta parte el precio de su joya de la corona de forma definitiva y global. Este nuevo estándar de precios se convierte en la norma oficial a partir del 31 de mayo de 2026, dejando atrás la fase promocional. Una auténtica locura.
La matemática de hundir el mercado de la IA
Si miramos los números fríos, la agresividad financiera de la medida asusta bastante. Hablamos de que en dólares, la tarifa se desploma hasta los 0,003625 por millón de tokens de entrada con caché. Si tu solicitud inicial no utiliza caché, el precio sube a 0,435 dólares, y ese millón de tokens de salida se queda en apenas 0,87 dólares. Las matemáticas no mienten, han roto la baraja.
Básicamente, esto significa que el nuevo V4-Pro resulta entre 29 y 34 veces más barato que bestias de la competencia directa como el mismísimo GPT-5.5 de OpenAI o el potente Claude Opus 6 de Anthropic. Una brecha de precio tan absurda cambia por completo las reglas del juego para cualquier desarrollador de software. Si estabas dudando qué plataforma integrar en tu próxima aplicación, aquí tienes un argumento de peso.
También te puede interesar:NVIDIA Apoya a DeepSeek V4 con Soporte para Blackwell Ultra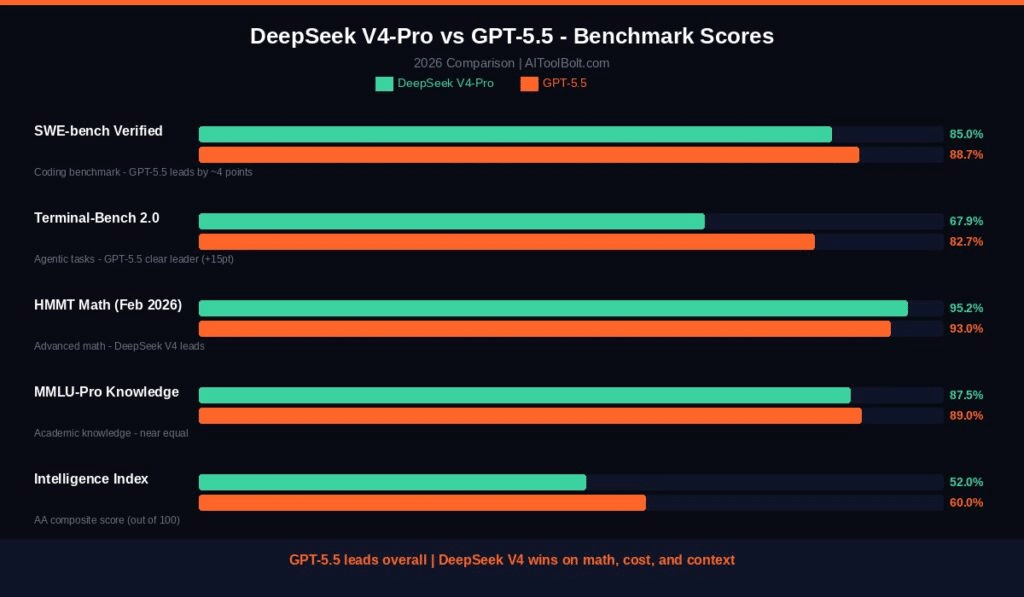
Como era de esperar, esta guerra de precios masiva no es un accidente ni un simple error contable de la directiva. La táctica agresiva recuerda muchísimo a la que usaron los fabricantes chinos hace unos años para inundar el mercado tecnológico de memoria RAM DDR4. Al aplicar descuentos estructurales de hasta el 50 %, forzaron a todo el sector mundial a adaptarse a la baja. O reduces tus márgenes de beneficio hasta el subsuelo, o despídete de tu cuota de mercado.
Hardware propio: el secreto tras el V4-Pro
Pero claro, la letra pequeña es entender cómo demonios consiguen sostener estas tarifas irrisorias sin ir directos a la quiebra en un par de meses. La respuesta no está en la magia del software, sino en el silicio puro y duro. Todo el entramado del DeepSeek-V4 se diseñó desde cero para exprimir al máximo los chips de IA de Huawei, funcionando a pleno rendimiento dentro del denso ecosistema Ascend.
De hecho, la propia compañía tecnológica ya había dejado caer en el pasado que sus costes operativos de inferencia caerían en picado tarde o temprano. Solo necesitaban que los nuevos procesadores Ascend 950 estuvieran disponibles en un volumen muchísimo mayor. Esa independencia total del hardware tradicional estadounidense parece ser la gasolina que alimenta esta estrategia. Ni siquiera el dominio de NVIDIA les hace sudar.

Por si fuera poco, las especificaciones técnicas brutas del modelo justifican el pánico evidente en las oficinas de Silicon Valley. Tanto la versión Pro como la orientada a velocidad extrema, V4-Flash, aguantan sin despeinarse una monstruosa ventana de contexto de 1 millón de tokens. Además, soportan de forma nativa tanto flujos de razonamiento profundo como respuestas directas e inmediatas. Te sirve para absolutamente todo.
También te puede interesar:NVIDIA Apoya a DeepSeek V4 con Soporte para Blackwell UltraEl paraíso de los tokens y el sistema RAG
A ello se le suma otra capacidad oculta que va a encantar a los programadores más exigentes del panorama actual. Este sistema permite generar salidas máximas larguísimas, alcanzando el espectacular tope de 384.000 tokens generados de una sola sentada. Y eso abre la puerta a maravillas técnicas de nueva generación sin que la máquina colapse. Te permite automatizar flujos de trabajo inmensos, analizar bases documentales legales kilométricas o programar agentes autónomos complejos con memoria persistente.
En concreto, el abaratamiento radical en la entrada con caché es un caramelo técnico irresistible para arquitecturas RAG complejas. Si estás montando un asistente empresarial interno que debe leer el mismo manual técnico de mil páginas una y otra vez cada día, el coste mensual ya no es un problema insalvable. El ahorro anual directo al reutilizar ese contexto preprocesado puede ser de cientos de miles de euros para una start-up en crecimiento. Así de contundente.

Evidentemente, han sido listos y han replicado a la perfección la salida estructurada en JSON y las siempre útiles llamadas a herramientas externas. Todo ello manteniendo compatibilidad casi fotocopiada con los formatos de prompt estándar que usan OpenAI y Anthropic. Migrar tu base de código entera para abaratar costes drásticamente es cuestión de reescribir un par de líneas en tu entorno de desarrollo.
El mercado tecnológico nos acaba de dar una lección acelerada de economía de escala y pura fuerza bruta. Ya no sirve de nada presumir en las keynotes de tener el modelo de lenguaje más listo del barrio si cada consulta compleja le cuesta un riñón a tus clientes. La pelota está ahora mismo en el tejado de Sam Altman y las grandes tecnológicas occidentales. Veremos si responden recortando sus astronómicas tarifas o si prefieren atrincherarse en la calidad premium de sus ecosistemas cerrados.

Me dedico al SEO y la monetización con proyectos propios desde 2019. Un friki de las nuevas tecnologías desde que tengo uso de razón.
Estoy loco por la Inteligencia Artificial y la automatización.










¿Cómo está el asunto de la privacidad de DeepSeek frente a la competencia?