

A principios de 2025, la irrupción de DeepSeek nos demostró que el monopolio estadounidense de la inteligencia artificial no era intocable, provocando un terremoto financiero que sacudió hasta las mismísimas acciones de NVIDIA. Hoy, la historia parece repetirse. La tecnológica china Zhipu AI acaba de lanzar GLM-5.2, un misil directo a la línea de flotación de gigantes corporativos como OpenAI, Google o Anthropic.
Hablamos de la versión más reciente de la familia GLM, un modelo que abraza el código abierto y que rinde de tú a tú con los referentes indiscutibles del sector. Y no, no estamos ante una promesa vacía para captar inversores. Es un avance respaldado por años de experiencia de la compañía en su mercado local.
GLM-5.2 y la locura del millón de tokens para programar sin pausas
Si analizamos las tripas de este lanzamiento, lo primero que asusta es su pura escala operativa. GLM-5.2 llega al mercado equipado con una ventana de contexto monstruosa: un millón de tokens. Básicamente, podrías volcar bases de código gigantescas, manuales enteros y miles de líneas de logs, y la IA ni se inmuta.
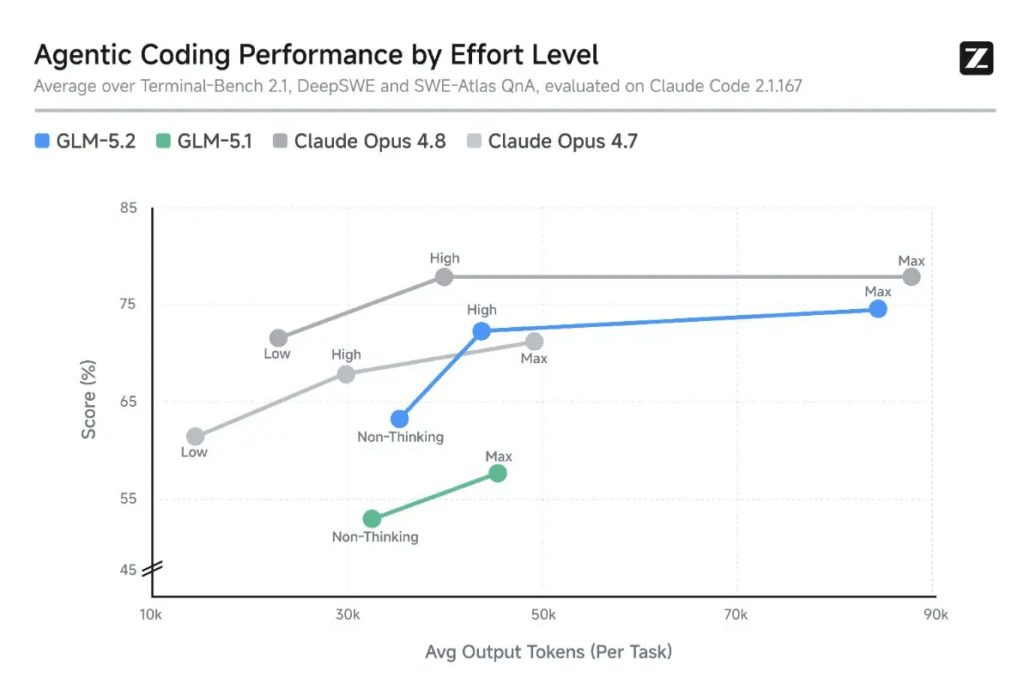
El motivo de esta decisión arquitectónica es muy concreto y ambicioso. Zhipu AI ha diseñado este modelo expresamente para dominar lo que en el sector conocemos como «tareas de largo horizonte«. Te lo traduzco: son esos proyectos complejos de programación que exigen varias horas de ejecución y revisión continua. Tareas áridas como la construcción de compiladores, la optimización profunda de kernels o el desarrollo de servicios pesados listos para producción.
También te puede interesar:Aterriza GLM-5.2, la Nueva IA Open Source de China que Desafía a Silicon ValleyPero claro, la letra pequeña de los LLM actuales es que casi siempre pierden el hilo o alucinan cuando la sesión de trabajo se alarga en exceso. Para evitar esta temida pérdida de coherencia, los ingenieros chinos han entrenado a GLM-5.2 enfocándose exclusivamente en escenarios de agentes de código con contextos kilométricos. Una jugada maestra.
Rendimiento puro: pisando los talones a Claude Opus 4.8
A ello se le suma una característica técnica muy demandada: un sistema nativo de control del nivel de esfuerzo. Es decir, tú como usuario decides el equilibrio exacto entre la velocidad de respuesta y la profundidad del razonamiento de la máquina. ¿Tienes un bug tonto? Activas el modo rápido. ¿Necesitas refactorizar una arquitectura entera? Le pides razonamiento intensivo. Así de simple.
Y es al mirar los números cuando entendemos la magnitud del asunto. En el exigente benchmark FrontierSWE, GLM-5.2 supera a GPT-5.5 en un 1% y destroza al popular Claude Opus 4.7 con una ventaja del 11%. Unas cifras mareantes para un modelo abierto.
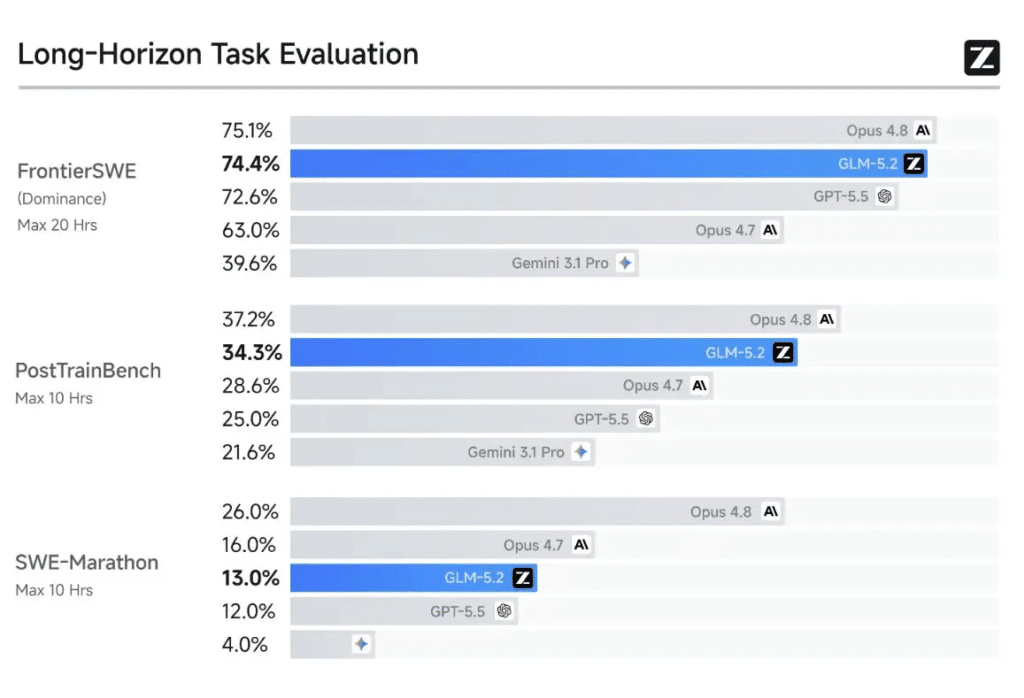
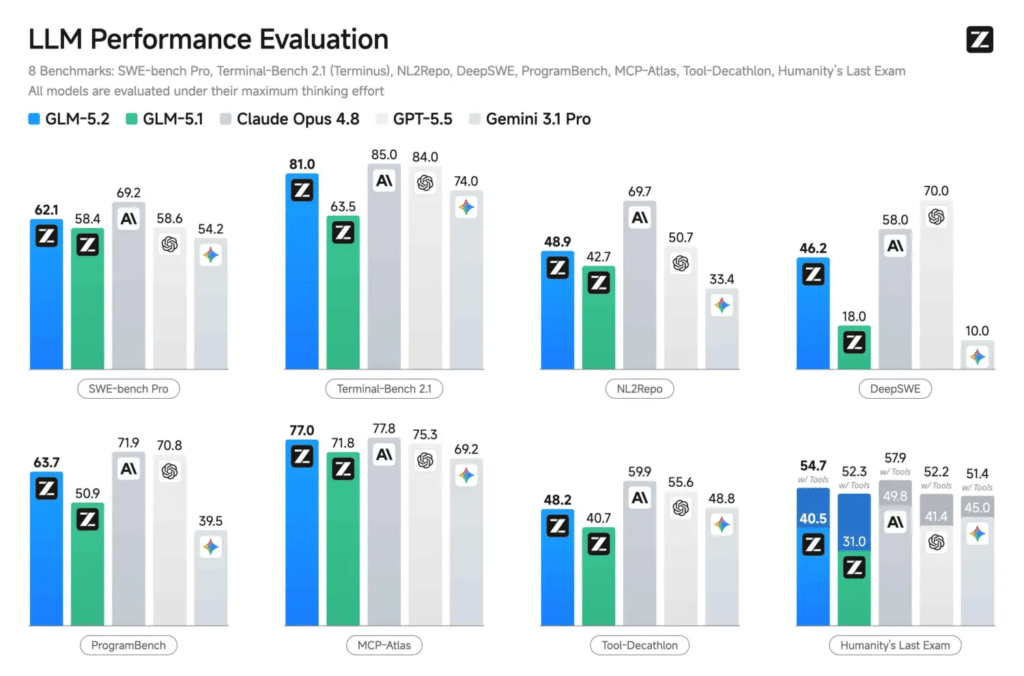
Evidentemente, el rey absoluto en la prueba FrontierSWE sigue siendo Claude Opus 4.8, pero el recién llegado asiático se ha quedado a un mísero punto porcentual de arrebatarle la corona. La tendencia es sólida: en Terminal-Bench 2.1 logra unos impresionantes 81.0 puntos frente a los 85.0 de Opus 4.8, y en la prueba SWE-Bench Pro alcanza una puntuación de 62.1.
También te puede interesar:Aterriza GLM-5.2, la Nueva IA Open Source de China que Desafía a Silicon ValleyCon este aluvión de datos técnicos, el debate queda zanjado. Se ha convertido oficialmente en el modelo de código abierto mejor clasificado en todas estas métricas de programación avanzada.
Licencia MIT y guerra de precios en el ecosistema de desarrolladores
Por si el rendimiento no fuera suficiente atractivo, Zhipu AI ha decidido no guardar su tecnología en un cajón bajo llave. Han liberado GLM-5.2 bajo la permisiva licencia MIT, fulminando de un plumazo las restricciones habituales que arrastran los modelos propietarios de Silicon Valley. Los pesos estructurales ya están colgados y listos para descargar en repositorios como HuggingFace o ModelScope.
A nivel de despliegue de software, la compatibilidad es total. El modelo funciona sin fricciones con frameworks de inferencia clave como vLLM, SGLang y los clásicos transformers. Además, los desarrolladores pueden exprimirlo a través del chat de Z.ai o integrándolo directamente en su día a día con agentes como ZCode, OpenCode o Claude Code. Si usas este último, basta con introducir la cadena «GLM-5.2[1m]» para despertar a la bestia con su millón de tokens de memoria.
Según han explicado detalladamente en una publicación en su blog, la estrategia también pasa por ser muy agresivos comercialmente. Los suscriptores de su GLM Coding Plan ya pueden utilizarlo hoy mismo. De hecho, han lanzado un órdago en forma de promoción temporal. Hasta finales del mes de septiembre, todo el uso que hagas del modelo durante las horas valle se facturará a coste cero y sin multiplicadores ocultos. Una locura comercial para ganar cuota de mercado rápido.
Viendo cómo se mueve el tablero, la brecha tecnológica entre los modelos privativos hipercaros y las alternativas de libre acceso se está difuminando a un ritmo que asusta. La pelota está ahora en el tejado de las grandes corporaciones occidentales. Veremos si responden bajando sus tarifas o si, por el contrario, asumen que la democratización técnica del código ya es imparable.

Me dedico al SEO y la monetización con proyectos propios desde 2019. Un friki de las nuevas tecnologías desde que tengo uso de razón.
Estoy loco por la Inteligencia Artificial y la automatización.






