

A veces parece que en OpenAI no duermen. Justo cuando creíamos que el mercado de los modelos ligeros estaba estabilizado, la compañía de Sam Altman acaba de soltar una bomba en el sector: GPT-5.4 mini y GPT-5.4 nano. Dos modelos diseñados obsesivamente para reventar los costes y llevar la latencia a su mínima expresión. Y no, no son versiones capadas hechas con prisas. Son auténticas bestias pensadas para entornos de producción donde cada milisegundo de respuesta vale oro.
Y es que la jugada comercial es de manual. En lugar de sacar un único mastodonte que te cobra hasta por respirar, han decidido fragmentar la oferta. El objetivo principal es que los desarrolladores utilicen estos modelos de OpenAI como motores para copilotos de código de altísimo volumen. Esto cambia radicalmente la forma en la que diseñamos el software actual. Una auténtica locura técnica.
La tiranía de los benchmarks: GPT-5.4 mini ni se inmuta
Si miramos los números, la mejora respecto a la generación anterior directamente asusta. El flamante GPT-5.4 mini es más del doble de rápido que el viejo GPT-5 mini en casi cualquier petición. No hablamos solo de escupir tokens a lo loco, sino de mantener una precisión quirúrgica asombrosa en tareas complejas. Han afinado la máquina al máximo nivel.
En concreto, el modelo logra un 54,4% en la prueba SWE-Bench Pro, destrozando el modesto 45,7% de su predecesor. Pero donde realmente saca músculo es en OSWorld-Verified. Ahí alcanza un brutal 72,1% frente al pobre 42,0% de la versión anterior. Básicamente, recorta la distancia de forma drástica con el modelo GPT-5.4 completo en programación y gestión de agentes autónomos. Así de simple.
También te puede interesar:La IA Erótica Presume de Automatización, el Problema es Quién Responde Realmente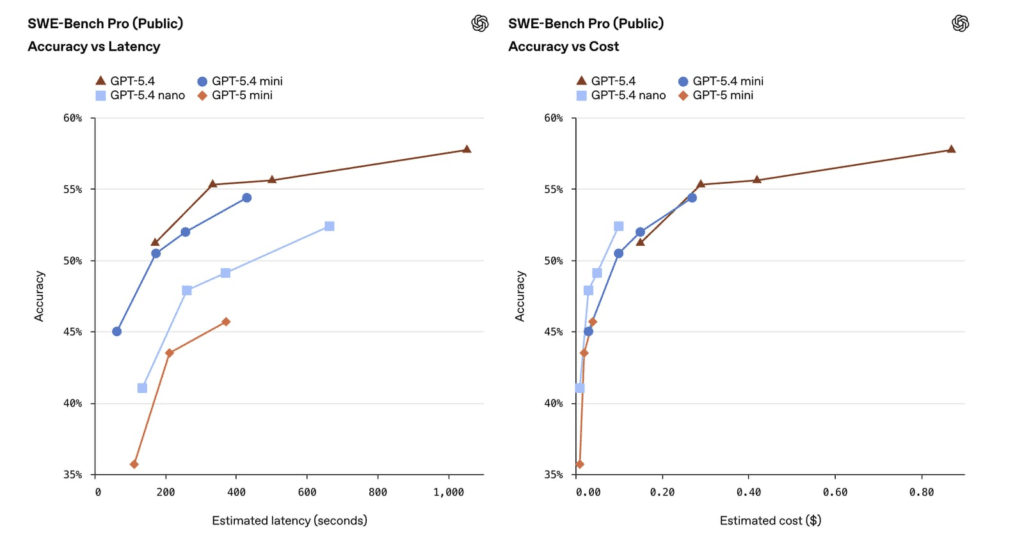
Por otro lado, nos topamos con el hermano menor. El GPT-5.4 nano aterriza exclusivamente en la API como la opción más extrema en economía. Pero no te dejes engañar por el apellido «nano», porque también reparte leña. Pese a situarse en un escalón inferior, supera con soltura al antiguo GPT-5 mini en pruebas exigentes como Toolathlon. Nada mal para el benjamín del catálogo.
Precios de derribo y una ventana de contexto gigante
Evidentemente, todo este rendimiento no sirve de nada si usarlo arruina tu start-up a final de mes. Aquí es donde OpenAI ha roto el mercado por completo. GPT-5.4 mini tiene un coste de 0,75 dólares por millón de tokens de entrada y 4,50 dólares en la salida. Una tarifa hipercompetitiva para el volumen de inferencia que maneja.
Por si fuera poco, el modelo nano tira los precios por los suelos de forma escandalosa. Hablamos de apenas 0,20 dólares en entrada y 1,25 dólares en salida por millón de tokens. Es decir, montar un enjambre de subagentes para que clasifiquen o extraigan información en tiempo real ahora cuesta pura calderilla. Un regalo caído del cielo para los programadores.

A ello se le suma el mantenimiento de unas especificaciones de hardware envidiables. Ambos modelos presumen de una ventana de contexto de 400.000 tokens, con un límite de salida espectacular de 128.000 tokens. Puedes meter bases de código gigantescas en un solo prompt por un precio ridículo. Ni sudan procesando tanta información de golpe.
También te puede interesar:La IA Erótica Presume de Automatización, el Problema es Quién Responde RealmenteAdemás, ofrecen una versatilidad tremenda para el día a día. Los dos aceptan entradas de texto e imagen, soportando salidas estructuradas y llamadas a funciones nativas. Están diseñados desde su núcleo para operar en arquitecturas multi-agente. El modelo grande planifica las ideas maestras y estos pequeñines ejecutan el trabajo sucio.
Microsoft se frota las manos ante la baja latencia
Pero claro, la estrategia de expansión no se limita solo al código puro y duro. OpenAI ha tejido una red que abarca todo su ecosistema para jubilar lo obsoleto. Con este lanzamiento, GPT-5.4 sustituye al anterior GPT-5.2 en la API comercial y fulmina al antiguo GPT-5.3-Codex. Renovación total en sus servidores.
Si nos centramos en el entorno de Codex, el nuevo mini consume apenas el 30% de la cuota del modelo principal. Esto facilita muchísimo delegar tareas repetitivas a inteligencias más económicas sin agotar los límites de tu plan. Una eficiencia brutal para optimizar recursos de forma inteligente.
De hecho, si eres un usuario normal de ChatGPT, también tienes tu porción del pastel. GPT-5.4 mini ya está activo para las cuentas Free y Go mediante la opción Thinking. Actúa también como seguro de vida vital para los usuarios de pago cuando la red principal colapsa por exceso de tráfico. Un movimiento brillante para que el servicio no caiga nunca.
Como era de esperar, los grandes socios tecnológicos se han lanzado de cabeza. Microsoft ya ha integrado ambos modelos en su plataforma Foundry, con disponibilidad inmediata en Estados Unidos y muy pronto en Europa. Los posicionan como la capa de baja latencia definitiva para sistemas RAG. Un conducto ultra rápido para recuperar datos empresariales al instante.
Todo este despliegue deja una directriz clarísima para el futuro de la industria. OpenAI no se conforma con tener el razonamiento más avanzado, quiere ser la dueña absoluta de la cadena de montaje de la IA. El modelo pesado piensa, planifica y dirige, y la gama mini y nano ejecuta sin descanso a un precio imbatible.
Start-ups de análisis de datos como Hebbia ya confirman que esta nueva dupla rinde igual o mejor que sus alternativas a una fracción mínima del coste. La guerra por abaratar la inferencia masiva acaba de saltar por los aires definitivamente. La pelota está ahora en el tejado de Google y Anthropic para ver cómo devuelven este golpe maestro.

Me dedico al SEO y la monetización con proyectos propios desde 2019. Un friki de las nuevas tecnologías desde que tengo uso de razón.
Estoy loco por la Inteligencia Artificial y la automatización.









