

Llevamos años acostumbrados a hablar con la inteligencia artificial como si usáramos un viejo walkie-talkie. Tú hablas, sueltas el botón, esperas unos segundos y la máquina te responde. Esa fricción acaba de pasar a la historia. Thinking Machines ha soltado una auténtica bomba técnica al presentar sus nuevos modelos de interacción, diseñados para colaborar en tiempo real. Un sistema capaz de procesar audio, vídeo y texto a la vez, sin esperas desesperantes. Así de simple.
Y es que el gran cuello de botella de los grandes modelos de lenguaje actuales es precisamente la latencia. Nos venden conversaciones «naturales«, pero la realidad es que el software siempre necesita un turno completo para procesar el prompt antes de arrancar. Esta nueva arquitectura rompe esa barrera de un plumazo. Se acabó la dictadura de la interfaz basada en turnos de toda la vida.
La arquitectura de microturnos pulveriza la latencia en IA
Si miramos debajo del capó, la propuesta asusta bastante. La start-up ha diseñado una arquitectura completamente nueva basada en múltiples flujos y microturnos que operan en ventanas de apenas 200 milisegundos. Es un auténtico pestañeo. Una fracción de tiempo indetectable para el cerebro humano.
Básicamente, esto significa que el modelo genera salidas y mastica entradas de forma casi instantánea y constante. Ya no tienes que terminar tu frase para que el asistente empiece a reaccionar. Puedes interrumpirle a medias, hablar exactamente al mismo tiempo que la máquina o cambiar de tema sobre la marcha. El sistema ni se inmuta.
A ello se le suma lo que la compañía llama «conciencia temporal». La IA sabe exactamente en qué momento exacto de la conversación estáis, gestionando los diálogos en tiempo real como lo harías con un compañero de oficina. De esta forma, mantiene un intercambio bidireccional constante contigo. Todo de forma nativa, sin depender de torpes estructuras externas que traduzcan la voz a texto antes de saber qué hacer con ella.
Dos cerebros trabajando juntos: razonamiento asíncrono en la sombra
Pero claro, aquí surge una duda más que razonable. Si la IA tiene que responder a la velocidad de la luz, ¿cómo le da tiempo a pensar en tareas realmente complejas? Todos los que usamos estas herramientas sabemos que en inteligencia artificial, pensar rápido suele equivaler a alucinar más. La calidad cae en picado.
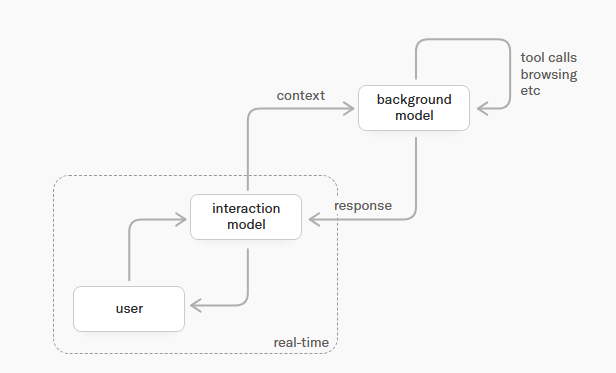
La solución de Thinking Machines pasa por un diseño de doble fondo muy inteligente. El ecosistema combina un modelo de interacción ultrarrápido con un segundo modelo asíncrono que trabaja duro en segundo plano. Mientras el primer cerebro gestiona la charla, el tono de voz y el contacto visual, el segundo se remanga para hacer el trabajo sucio y pesado de la computación pura.
Es decir, si le pides que analice una base de datos gigante mientras debatís sobre el enfoque del proyecto, el modelo principal te dirá que se pone a ello y seguirá conversando contigo sobre otros temas. Mientras tanto, el cerebro en la sombra tira de razonamiento extendido y usa herramientas externas. Una vez que termina su tarea, inyecta los resultados en la charla principal de manera fluida y natural.
El modelo TML-Interaction-Small ya avisa en los benchmarks
Evidentemente, hacer promesas millonarias sobre el papel es gratis. El sector está plagado de vende humos y de vídeos pregrabados que luego no aguantan el mínimo roce con el mundo real. Sin embargo, los primeros benchmarks internos sugieren que aquí hay músculo de verdad para cambiar las cosas.
En concreto, la versión más ligera de esta familia, bautizada directamente como TML-Interaction-Small, ya está superando a modelos consolidados de la competencia en métricas de pura inteligencia y calidad de interacción humana. Su capacidad para mostrar una baja latencia combinada con una respuesta multimodal robusta está marcando un nuevo estándar en la industria.
La letra pequeña de este anuncio es que, por ahora, esta maravilla tecnológica no está instalada en tu ordenador. Se trata de una vista previa de investigación que solo está disponible para un grupo muy cerrado de investigadores de IA. El público objetivo inicial de la empresa son los desarrolladores y las grandes organizaciones que buscan llevar la colaboración humano-IA al siguiente nivel, asegurándose de mantener siempre al trabajador humano en el centro del proceso y la toma de decisiones.
Se espera que abran el grifo para ofrecer un acceso mucho más amplio a lo largo de este mismo año. Hemos superado por fin la fase primitiva del chat de texto plano y estamos entrando de lleno en la era de los compañeros virtuales hiperreactivos. Veremos cuánto tardan en responder los grandes pesos pesados de Silicon Valley. La pelota está ahora en su tejado.

Me dedico al SEO y la monetización con proyectos propios desde 2019. Un friki de las nuevas tecnologías desde que tengo uso de razón.
Estoy loco por la Inteligencia Artificial y la automatización.






